728x90
LLM이 있을 때 모델 전체를 파인 튜닝하는 것은 Full Fine Tuning
기존 LLM은 고정해두고 일부 파라미털르 추가하여 학습하는 것이 LoRA Tuning
학습 시 LoRA Tuning 은 더 적은 리소스로 학습 가능하며 상황에 따라서 Full Fine Tuning 보다 성능이 우수함
vLLM으로 Multi LoRA Serving 을 사용하면 하나의 LLM으로 다수의 모델 Serving 효과를 얻을 수 있음
- LoRA Tuning
- LoRA Tuning은 기존 LLM 파라미터는 고정하고, 아래의 그림에서 초록색 박스와 같이 A, B 행렬만 학습한다.
- 파라미터 W(d x d)가 LLM이라고 한다면, LoRA Tuning은 W는 학습하지 않는다.
- LoRA Tuning은 행렬 A(d, r)과 행렬 B(r, d)를 학습한다.
- 입력과 출력 d의 차원이 100이라고 가정하자.
- Full Fine Tuning: 10,000개의 파라미터 학습.
- 행렬 W의 크기: 100 x 100
- LoRA 튜닝을 위한 값 r은 정해주는 값이다.
- 만약 r을 4로 한다면?
- LoRA 튜닝: 800개의 파라미터 학습.
- A 행렬(100 x 4), B 행렬(4 x 100)

- 의문점: 추가 파라미터가 붙으니까 모델 용량 자체는 커질텐데 왜 학습할 때 자원이 절약되는건가?
- GPU 메모리에는 ‘모델’만 올라가는 것이 아니라 모델 업데이트를 위한 값인 ‘옵티마이저 상태’라는 것도 저장됨.
- LoRA Tuning 시에는 모델 업데이트 시에 사용되는 ‘옵티마이저 상태’ 값이 현저하게 줄어들게 됨.

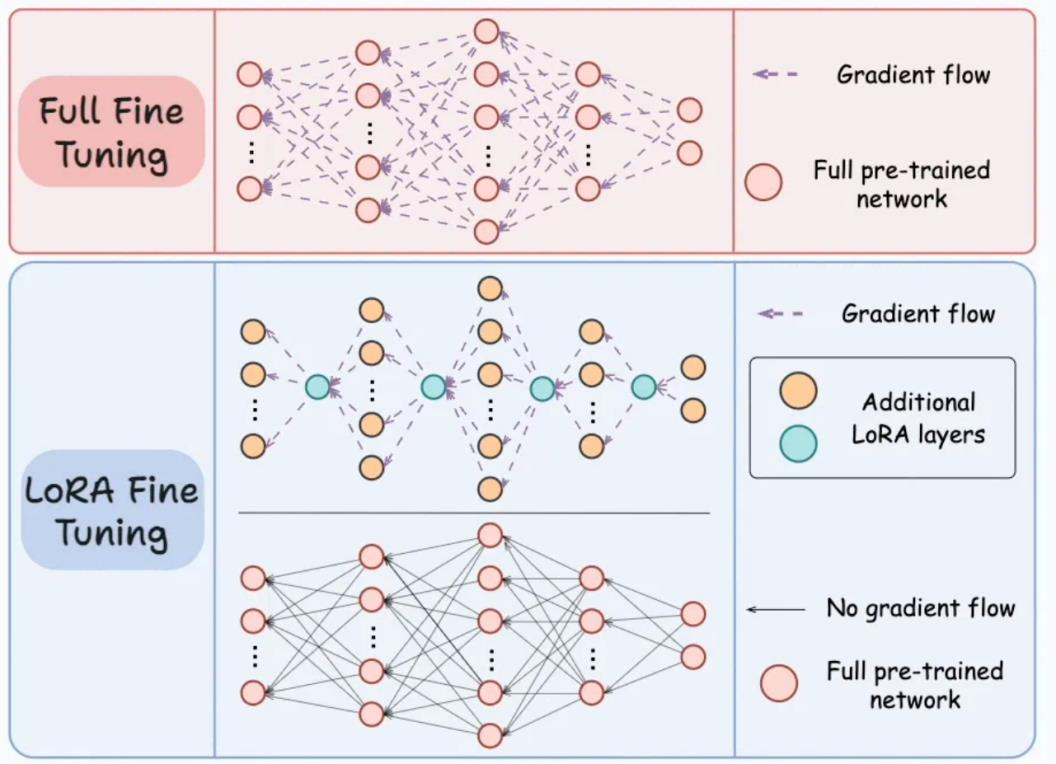
- Full Finetuning과 LoRA를 비교한 그림.
- LoRA의 경우 Adapters라는 것이 추가.
- LoRA의 경우 옵티마이저 상태 값 데이터가 매우 작아진 것을 보여주는 그림.
- 여기서 Adapters는 행렬 A와 B를 의미한다.
학습에 영향을 주는 LoRA 파라미터
- 행렬 A와 B를 만들 때 r 값을 몇으로 하느냐에 따라서 행렬의 크기가 결정된다.
- 파라미터 r의 값을 크게 하면 모델의 용량(capacity)을 크게 할 수 있고, 작게하면 모델의 용량을 줄인다.
- 크게, 작게에는 정해진 정답이 없다. 이는 성능에 영향을 주는 요소이다. (모델 크기에 따른 Overfitting 영향)


- R 외에도 알파 값은 기존 파라미터에 얼만큼 영향을 미치느냐를 결정한다.
- 행렬 A와 B를 곱한 부분을 W와 동일하게 더하는 것도 가능하며
- 행렬 A와 B를 더 중요하게 고려하게 하는 것도 가능하다.
- 이는 (알파/r)의 값으로 정해진다.
- 예를 들어서 알파가 16이고 r이 8이면 16을 8로 나눈 2만큼
- 행렬 A와 B에 곱한 후에 기존 파라미터에 더한다.
- 따라서 알파가 커질수록 LoRA 학습한 행렬 A와 B의 영향력이 커진다.


- lora_alpha=16
- 이는 LoRA의 스케일링 factor입니다.
- LoRA 업데이트의 강도를 조절합니다.
- 값이 클수록 LoRA의 영향력이 커집니다.
- 일반적으로 r 값의 2배로 설정하는 것이 좋습니다.
- lora_dropout=0.1
- LoRA 레이어에 적용되는 드롭아웃 비율입니다.
- 0.1은 10%의 뉴런이 랜덤하게 비활성화됨을 의미합니다.
- 과적합을 방지하고 모델의 일반화 성능을 향상하는 데 도움이 됩니다.
- r=64
- LoRA의 랭크(rank)를 설정합니다.
- 이 값은 LoRA 행렬의 차원을 결정합니다.
- 값이 클수록 모델의 표현력이 증가하지만, 학습해야 할 파라미터 수 도 증가합니다.
- 일반적으로 8에서 64 사이의 값을 사용합니다.
실제 RAG 파인 튜닝 코드
- 주피터 노트북을 실행 후 아래의 코드를 그대로 따라하셔서 RAG 파인 튜닝 모델을 만들어보세요.
- 아래 코드는 실제로는 구글 Colab에서는 돌아가지 않습니다. A100 GPU로 학습되었습니다.
- Runpod이라는 유료 클라우드를 사용하였으며 학습 비용은 약 3천원 이내로 Runpod 사용법은 뒤 슬라이드 참고.
- 여기서는 학습 전, 후 달라진 모습만 확인해봅시다!
- https://colab.research.google.com/drive/15yduyaJLDBy6bDVOGNEAYoIIz-7oTgL_?usp=sharing
rag - tuning_example.ipynb
Colab notebook
colab.research.google.com
- 위 실습은 싱글 GPU 학습 + 허깅페이스 인퍼런스입니다
Runpod
- Billing에서 결제를 진행하였다고 가정.
- Pods > Deploy

LLM 학습을 위해서는 다수의 A100 GPU가 필요할 수 있다.
예를 들어 아래의 그림에서는 A100 SXM을 선택한다.
사용할 GPU를 선택한다. 여기서는 2개를 선택하였다.

디스크 용량을 수정하기 위해서 Edit Template를 선택한다.

- 학습 시 필요한 Disk 용량이 가늠되지 않는다면 가급적 전부 넉넉하게 수정.
- LLM 다운로드를 위해서는 Container Disk가 넉넉해야 한다. (50 이상 권장)
- Volume Disk는 이 서버가 정지되었을 때 작업했던 정보를 보관하기 위한 영구 용량.
- Volume Disk가 0이면 서버가 정지되었을 때 작업했던 정보를 모두 잃는다.

- 주피터 노트북 열기
- [Start Jupyter Notebook] 버튼을 클릭.
- 이어서 [Deploy On-Deman] 버튼을 클릭.
이제 서버 셋팅 작업이 끝났다. [Connect] 버튼을 눌러준다

Connect to Jupyter Lab [Port 8888]을 클릭한다.

[Python 3]을 클릭하면 우측 그림과 같이 파이썬 실습 환경이 실행된다.


좌측 상단의 [File] > [Save Notebook As]를 클릭하여 노트북의 이름을 변경할 수 있다.


728x90
'AI' 카테고리의 다른 글
| Function Calling 예시 - 행거 챗봇 예시 (0) | 2025.04.09 |
|---|---|
| 여러 문서에서 찾아서 답변하는 챗봇 만들기 (0) | 2025.04.08 |
| RAG를 위한 파인 튜닝 데이터셋 실습 EDA (0) | 2025.04.04 |
| Fine-tuning For RAG (0) | 2025.04.04 |
| MultipleNegativesRankingLoss를 활용한 임베딩 파인 튜닝 (0) | 2025.04.04 |

