RAFT: Adapting Language Model to Domain Specific RAG
- UC Berkeley 논문
- 사용자의 질문과 연관된 문서와 정답과 연관이 없는 문서를 섞어서 검색 결과로 가정하고 데이터셋을 구축
- 이 때 연관이 없는 문서들을 negative documents라고 하며 학습에 도움을 주게 된다.
- 이는 Fine-tuning 시 답변과 관련 없는 정보를 식별하는 능력을 향상시키기 때문이다.

- 파인 튜닝 전, 후 LLAMA2의 RAG 성능 차이는 매우 크게 나는 것을 볼 수 있음
- LLAMA2-7B를 파인 튜닝한 것이 GPT-3.5 에 RAG 를 한 것보다 성능이 더 좋음
- 원문을 인용하여 답변하게 하면 성능 Up
- 원문을 인용해야 하므로 할루시네이션 억제
- 일종의 Chain of Thought 프롬프트 엔지니어링
- Fine-tuning 시에도 원문 인용을 강제하면 좋다.
RAG-optimized model
Cohere 의 RAG-optimized model
- 이미 RAG에 대해서 학습이 되어진 채로 공개된 RAG 특화 모델들이 존재함
- 해당 모델들이 사용한 RAG 프롬프트를 참고하면, RAG 를 Fine-tuning 할 때 어떤 프롬프트를 사용하면 될 지 힌ㅌ를 얻을 수 있다.
- 예로 Cohere (RAG를 주력 기능으로 삼고 있음) 에서 나온 Command R, Command R+ 가 이에 해당된다.
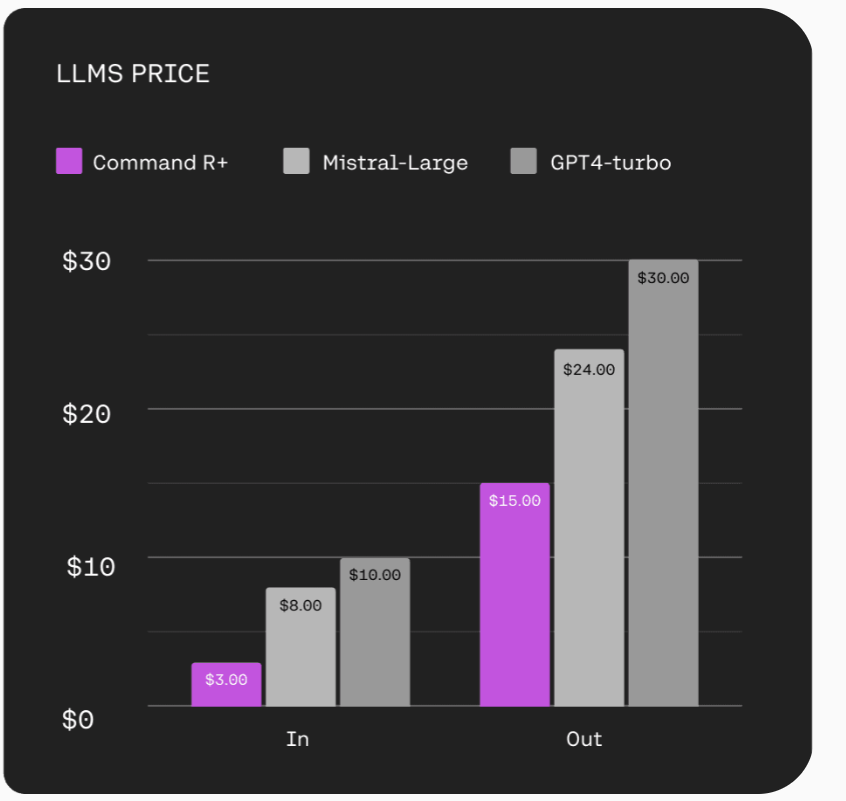
Cohere의 RAG Prompt
다음은 Cohere 에서 사용하고 있는 RAG Prompt 이다.

다음은 Cohere 에서 사용하고 있는 RAG Prompt 이다

Orion-14B-RAG
- Orion 의 경우, 다양한 태스크에 맞춰서 Fine-tuning 된 모델들을 공개
- 이 중 RAG에 특화된 모델이 존재함
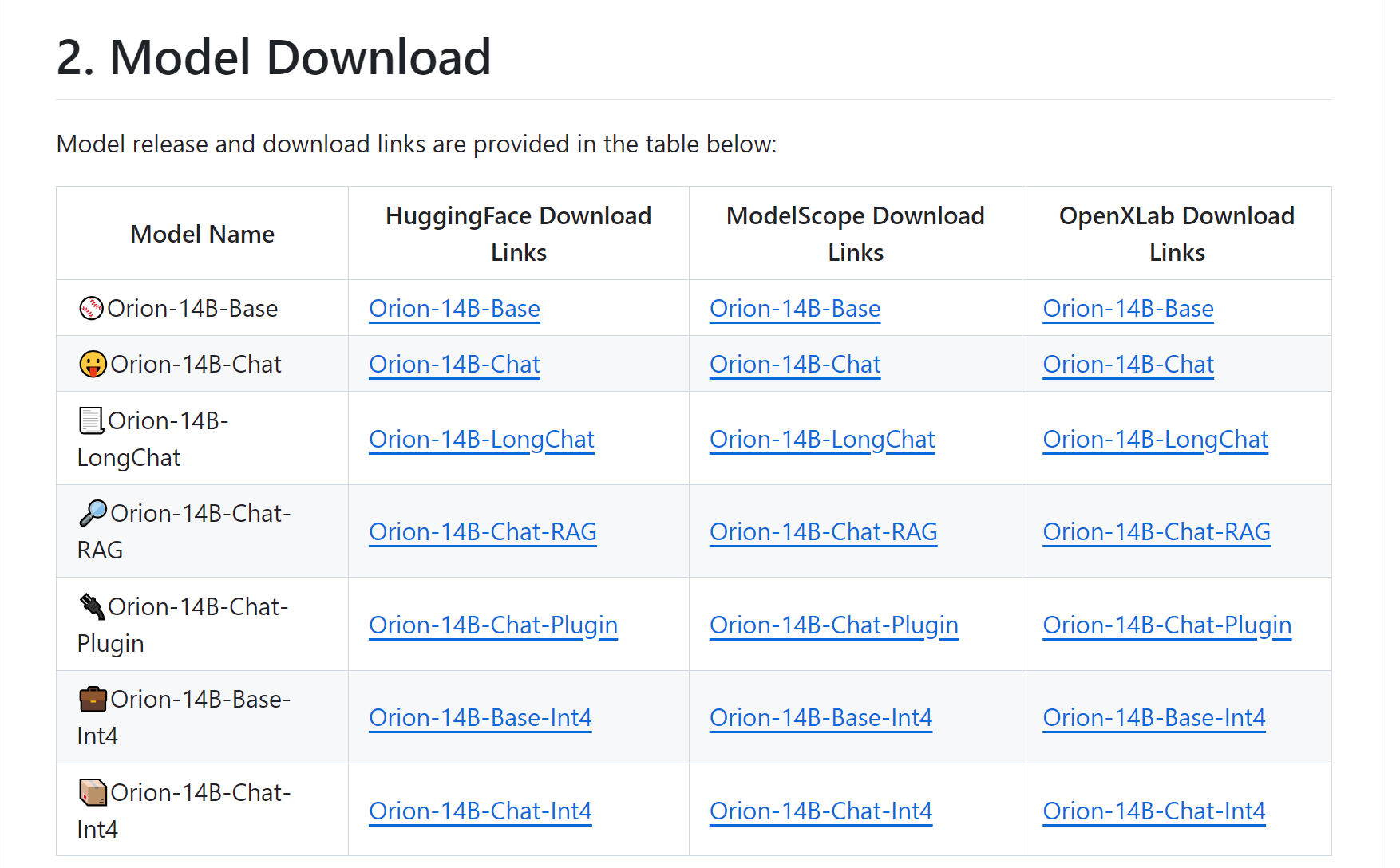
- 다음은 Orion에서 사용하고 있는 RAG Prompt 이다.

답변 예시
- 답변 작성 시 출처를 반드시 명기하도록 하여 답변 성능을 높이고 신뢰성을 높인다.

GPT-4의 웹 검색 답변 예시
- 답변 작성 시 출처를 반드시 명기하도록 하여 답변 성능을 높이고 신뢰성을 높인다.

RAG를 위한 파인 튜닝 가이드: 출처 or 인용
- 방법1: Orion Prompt 방식과 같이 출처를 뒤에 명시적으로 남기도록 더라도 실제로 RAG 성능이 오르는 것을 확인할 수 있음. 또한, 이 방식은 평가셋이 존재할 때 실제 정답 문서를 인용했는지를 확인해서 RAG의 정량적인 평가를 할 수 있다는 장점 또한 존재함.
- 방법2: RAFT 논문 방식의 **quote** 인용이나 Cohere 방식의 <co:문서 번호></co:문서 번호> 방식을 사용하는 것 또한 뛰어난 성능을 얻을 수 있음. 이는 모델이 인용을 하도록 강제하므로서
억지로 지어내는 이야기를 애초에 답변에 쓸 수 없도록 강제하는 효과가 있음.
Cohere 방식과 같이 인용 시 문서 번호를 기재한다면 방법1과 마찬가지로 평가셋이 존재할 때 정답 문서를 인용했는지를 확인해서 RAG의 정량적인 평가를 할 수 있다는 장점 또한 존재함.
RAG 를 위한 파인 튜닝 데이터셋 제작 방법
- 10B 이내의 모델은 매우 민감. RAG 파인튜닝을 한다면 다음과 같은 사항들을 반드시 명심해야 함 (진짜진짜 매우매우 중요)
- GPT-4 API와 같은 강력한 모델 API로 방법 1 또는 방법 2 등 원하는 방향으로 답변을 작성하도록 하고 레이블로 사용
- 질문과 상관없는 문서가 검색되었을 때를 가정하여 Negative Sample 을 반드시 잘 구축할 것.
- Negative Sample 은 RAG로 입문한 분들에게 생소할지 몰라도 NLP 엔지니어분들에게는 매우 친숙한 개념이다. 따라서 검색하면 어떤 의미인지 많이 나오니 공부해야함
- 일반적으로 임베딩 모델이나 BM-25 를 사용하여 질문에 대해서 실제 검색 문서를 검색하여 구축하는 경우가 많다
- 참고하면 좋은 논문 : https://arxiv.org/abs/2407.15831
NV-Retriever: Improving text embedding models with effective hard-negative mining
Text embedding models have been popular for information retrieval applications such as semantic search and Question-Answering systems based on Retrieval-Augmented Generation (RAG). Those models are typically Transformer models that are fine-tuned with cont
arxiv.org
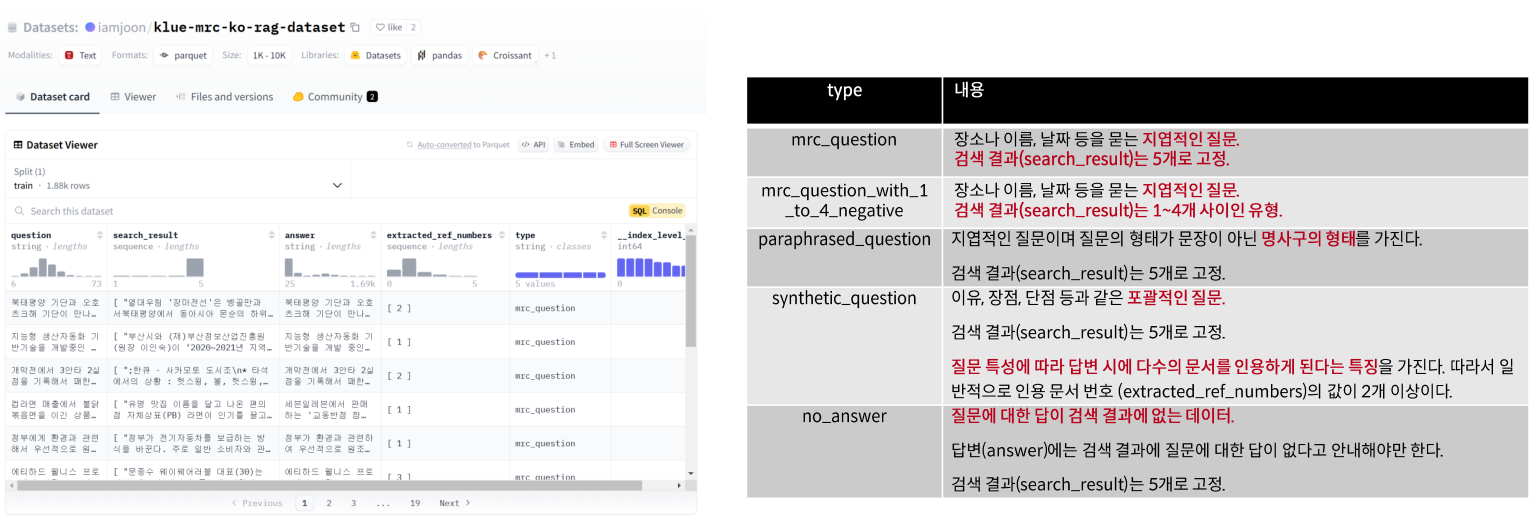
아래의 모든 유형의 데이터가 반드시 학습 데이터에 포함되어져 있어야 함.
- 단답을 유도하는 구체적이고 지엽적인 질문 ex) 12월 12일에 세미나가 열린 장소의 이름은 무엇인가?
- 단답이 아닐 수 있는 넓은 의미의 질문 ex) 세미나의 주제는?
- 명사구 형태로 끝나는 질문 (영어에도 대응할 것이라면 영어 질문 or 영어 검색 결과) ex) 12월 12일에 세미나가 열린 장소.
- 검색 결과가 1개일 때, 2개일 때 ... n개일 때
- 검색 결과에 질문에 대한 답이 전혀 없을 때
- 답변 시 검색 결과 중 1개의 문서만 인용하는 경우
- 답변 시 검색 결과 중 다수의 문서를 인용하는 경우
RAG를 위한 파인 튜닝 데이터셋
- 허깅페이스에 RAG 파인튜닝을 위해 앞서 설명한 대부분의 유형을 반영한 데이터를 제작하여 외부 공개.
- https://huggingface.co/datasets/iamjoon/klue-mrc-ko-rag-dataset
iamjoon/klue-mrc-ko-rag-dataset · Datasets at Hugging Face
[ "블리자드 엔터테인먼트(Blizzard Entertainment, Inc.)의 인기 디지털 카드 게임 하스스톤(Hearthstone®) e스포츠를 대표하는 세계 최고의 선수들 여덟 명이 챔피언의 전당에 이름을 올리기 위해 벌이는
huggingface.co
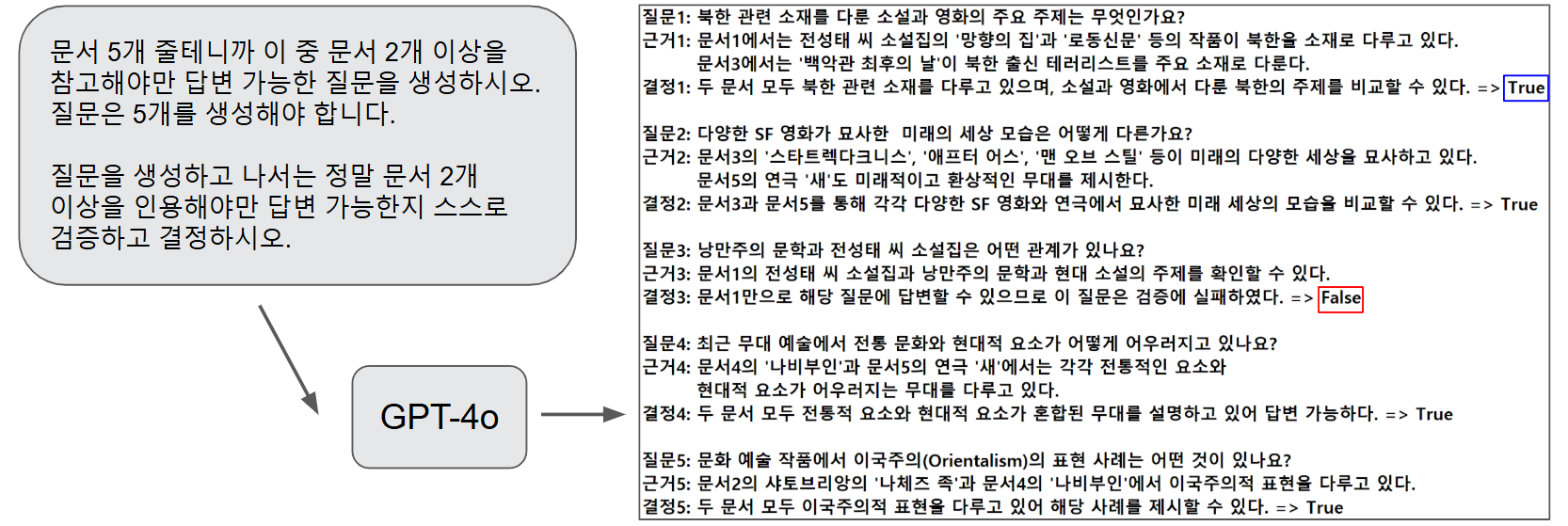
데이터 만드는 예시 (GPT-4와 프롬프트 엔지니어링)
- 단, 한 번의 호출로 GPT-4 가 데이터 5개를 동시에 만들고 스스로 검증하고 통과까지 시키는 예시이다.
'AI' 카테고리의 다른 글
| LoRA Tuning (0) | 2025.04.08 |
|---|---|
| RAG를 위한 파인 튜닝 데이터셋 실습 EDA (0) | 2025.04.04 |
| MultipleNegativesRankingLoss를 활용한 임베딩 파인 튜닝 (0) | 2025.04.04 |
| RAG 실습 이후 + LLM 추천 (0) | 2025.04.04 |
| RAG 서울 청년 정책 챗봇 실습 (0) | 2025.04.03 |


