딥러닝 모델은 수많은 파라미터와 복잡한 연산을 포함하고 있기 때문에, 이를 처리하는 데 막대한 연산 자원이 요구된다. 특히 딥러닝의 핵심 작업인 행렬 연산(Matrix Operations)은 매우 방대한 양의 데이터를 동시에 처리해야 하는데, 이러한 작업을 효율적으로 처리하기 위해 병렬 연산의 개념이 필수적이다.
GPU는 수천 개 이상의 코어를 통해 수많은 연산을 동시에 처리할 수 있는 병렬 처리 능력을 가지고 있어, 딥러닝 모델 학습 시 CPU에 비해 훨씬 더 빠르게 연산을 수행할 수 있다. 반면 CPU는 소수의 고성능 코어로 순차적인 작업에 강점을 가지지만, 병렬 연산의 효율성은 GPU에 미치지 못한다.
이를 비유하자면, CPU는 그림을 그릴 때 풍선을 하나씩 던져 그림을 완성하는 방식이라면, GPU는 여러 개의 풍선을 동시에 던져 더 빠르게 그림을 완성하는 방식으로 볼수 있다.
CPU

GPU

GPU의 이러한 특징은 특히 대량의 데이터를 동시에 처리해야 하는 딥러닝 학습에 유리하고, 주로 행렬 곱셈이나 벡터 연산과 같은 대규모 병렬 연산을 최적화하는 데 큰 도움이 된다.
실제로 GPU를 사용한 딥러닝 학습은 CPU에 비해 수십 배에서 수백 배 빠른 속도를 자랑한다.
데이터 작업하기
파이토치(PyTorch)에는 데이터 작업을 위한 기본 요소 두가지인 torch.utils.data.DataLoader 와 torch.utils.data.Dataset이 있다. Dataset은 샘플과 정답(label)을 저장하고, DataLoader 는 Dataset 을 반복 가능한 객체(iterable)로 감싸는 역할을 한다.
Fashion Mnist
이번 섹션에서는 Fashion MNIST 데이터를 활용하여 데이터 처리와 분류 작업을 실습을 진행해 볼건데 기존에 한번 이 데이터셋을 진행해 보았지만 처음부터 차근차근 다시 진행해보고자 한다.
Fashion MNIST는 머신러닝 및 딥러닝 모델 학습을 위한 대표적인 데이터셋 중 하나로, 10가지 종류의 의류 이미지로 구성되어 있으며, 데이터는 28x28 픽셀 크기의 흑백 이미지로 되어 있으며, 각 이미지에는 해당하는 의류의 레이블(label)이 포함되어 있다.
이 데이터는 티셔츠, 바지, 신발 등과 같은 의류 품목이 포함되어 있어, 현실 세계의 패션 이미지를 기반으로 한 분류 작업에 적합하다. Fashion MNIST의 10개 클래스는 다음과 같이 구성되어 있다.
- 티셔츠/탑 (T-shirt/top)
- 바지 (Trouser)
- 풀오버 (Pullover)
- 드레스 (Dress)
- 코트 (Coat)
- 샌들 (Sandal)
- 셔츠 (Shirt)
- 스니커즈 (Sneaker)
- 가방 (Bag)
- 앵클 부츠 (Ankle boot)
Fashion MNIST 데이터는 모델의 성능을 평가하거나 딥러닝 모델의 구조를 실험할 때 많이 사용되며, 다양한 신경망 구조를 적용해보고 그 성능을 비교하는 데 적합한 데이터셋이다.
아래 그림은 Fashion MNIST 데이터의 몇 가지 예시를 보여주는데. 각 클래스는 고유한 의류 품목을 나타내며, 이미지 데이터를 기반으로 모델이 올바르게 분류할 수 있도록 학습하는 것이 목표이다.

| import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor, Lambda, Compose import matplotlib.pyplot as plt |
| # 공개 데이터셋에서 학습 데이터를 내려받습니다. training_data = datasets.FashionMNIST( root="data", # dataset 경로 지정 train=True, # True로 선언시 학습 데이터를 가져옴 download=True, # 만일 없을 경우 download를 함 transform=ToTensor(), # tensor 형태로 변환시킴 ) # 공개 데이터셋에서 테스트 데이터를 내려받습니다. test_data = datasets.FashionMNIST( root="data", train=False, download=True, transform=ToTensor(), ) |
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz
100%|██████████| 26421880/26421880 [00:01<00:00, 17457450.48it/s]
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
100%|██████████| 29515/29515 [00:00<00:00, 302106.74it/s]
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
100%|██████████| 4422102/4422102 [00:00<00:00, 5602440.17it/s]
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
100%|██████████| 5148/5148 [00:00<00:00, 6511543.12it/s]Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
| batch_size = 64 # 데이터로더를 생성합니다. train_dataloader = DataLoader(training_data, batch_size=batch_size) # training_data를 batch_size크기로 dataloader에 올립니다. test_dataloader = DataLoader(test_data, batch_size=batch_size) for X, y in test_dataloader: print("Shape of X [N, C, H, W]: ", X.shape) print("Shape of y: ", y.shape, y.dtype) break |
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
모델 만들기(Fully Connected layer)
PyTorch에서 신경망 모델은 nn.Module_ 을 상속받는 클래스(class)를 생성하여 정의한다.
__init__ 함수에서 신경망의 계층(layer)들을 정의하고, forward 함수에서는 데이터가 신경망을 통과하는 방식을 결정한다(즉 신경망의 구조를 결정).
forward함수는 데이터가 각 계층을 거치며 수행되는 연산을 정의하는 곳으로, 모델의 순전파(forward propagation)가 이 함수에서 이루어지게 된다.
이번 섹션에서는 fully-connected layer를 사용한 신경망 모델을 실습해 보겠다. Fully-connected layer는 각 노드가 이전 계층의 모든 노드와 연결되어 있으며, 이로 인해 각 입력 데이터가 모든 가중치(weight)와 연산되는 구조를 가진다. 이는 신경망의 기본적인 구조 중 하나로, 입력 데이터를 저차원에서 고차원으로 변환하거나 고차원에서 저차원으로 변환하하는 데 주로 사용된다.
Fully-connected layer의 작동 방식은 다음과 같다:
- 각 입력 노드는 이전 계층의 모든 노드와 연결된다.
- 이 연결에서 가중치가 곱해진 후, 각 노드에서 합산되고 활성화 함수(Activation Function)가 적용 된다 .
- 이를 통해 출력값이 계산 된다 .
이를 그림으로 나타내면 아래와 같다.
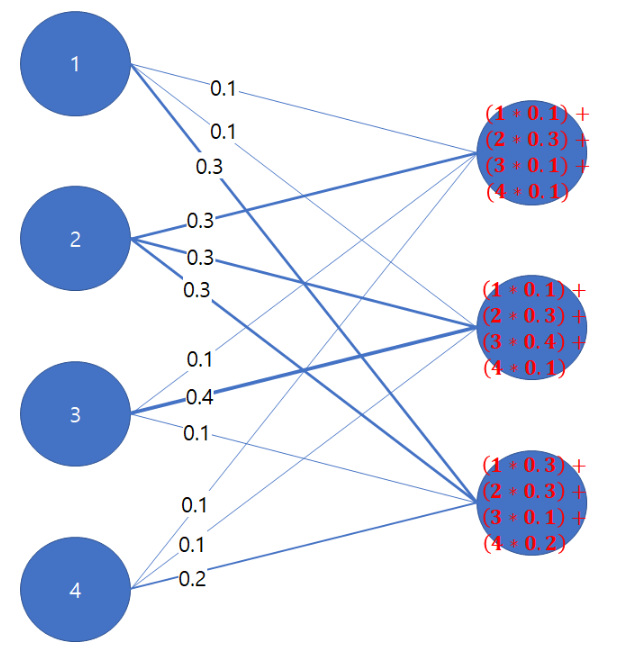
위 그림에서 볼 수 있듯이, 각 노드가 이전 층의 모든 노드와 연결되어 있는 구조이며. 이 방식은 데이터의 특성을 학습하는 데 매우 유용하지만, 입력 데이터의 크기가 커질수록 계산량이 급격히 증가할 수 있다. 이와 같이 fully-connected layer는 모델의 파라미터 수가 많아질 수 있으므로, 과적합(overfitting) 방지를 위해 정규화(regularization) 기법을 함께 사용하기도 한다.
Fully-connected layer는 일반적으로 다층 퍼셉트론(Multilayer Perceptron, MLP)에서 자주 사용되며, 다음과 같은 그림으로 나타낼 수 있다:
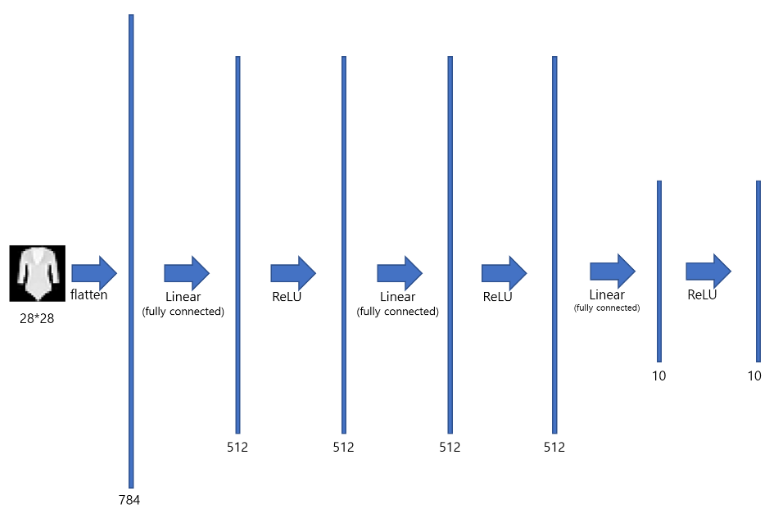
위와 같은 MLP는 아래와 같은 방식으로 구현할 수 있다.
| # 학습에 사용할 CPU나 GPU 장치를 얻습니다. device = "cuda" if torch.cuda.is_available() else "cpu" print("Using {} device".format(device)) # 모델을 정의합니다. class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() # 행렬을 1자로 쭉 핀것. # 블럭을 하나 만듦. self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 512), # 입력 크기는 28*28이고 출력 크기는 512인 linear 신경망을 만듭니다. nn.ReLU(), # 비선형 함수인 ReLU를 만듭니다. nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10), nn.ReLU() ) def forward(self, x): x = self.flatten(x) # 우선 28*28 크기를 갖는 이미지를 1*784의 크기의 벡터로 쭉 핍니다. logits = self.linear_relu_stack(x) # 앞서 정의했던 linear_relu_stack을 가져와 x를 입력으로 넣어 logit값을 출력으로 가져옵니다. return logits model = NeuralNetwork().to(device) print(model) |
Using cuda device
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)
모델 매개변수 최적화하기
| loss_fn = nn.CrossEntropyLoss() # loss 는 cross entropy loss를 사용할 것입니다. optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # optimizer로는 SGD를 사용할 것입니다. |
모델 학습하기
각 학습 단계(training loop)에서 모델은 (배치(batch)로 제공되는) 학습 데이터셋에 대한 예측을 수행하고, 예측 오류를 역전파하여 모델의 매개변수를 조정한다.
| def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) for batch, (X, y) in enumerate(dataloader): # 각 dataloader의 batch마다 연산을 진행합니다. X, y = X.to(device), y.to(device) # 예측 오류 계산 pred = model(X) loss = loss_fn(pred, y) # 역전파 optimizer.zero_grad() loss.backward() optimizer.step() if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") |
| epochs = 5 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model, loss_fn) print("Done!") |
Epoch 1
-------------------------------
loss: 2.306231 [ 0/60000]
loss: 2.304080 [ 6400/60000]
loss: 2.299260 [12800/60000]
loss: 2.297690 [19200/60000]
loss: 2.289892 [25600/60000]
loss: 2.271749 [32000/60000]
loss: 2.284267 [38400/60000]
loss: 2.264529 [44800/60000]
loss: 2.261097 [51200/60000]
loss: 2.256736 [57600/60000]
Test Error:
Accuracy: 27.6%, Avg loss: 2.258848
Epoch 2
-------------------------------
loss: 2.262220 [ 0/60000]
loss: 2.280088 [ 6400/60000]
loss: 2.263246 [12800/60000]
loss: 2.265647 [19200/60000]
loss: 2.243679 [25600/60000]
loss: 2.209622 [32000/60000]
loss: 2.239355 [38400/60000]
loss: 2.203352 [44800/60000]
loss: 2.201662 [51200/60000]
loss: 2.195778 [57600/60000]
Test Error:
Accuracy: 35.4%, Avg loss: 2.192072
Epoch 3
-------------------------------
loss: 2.214652 [ 0/60000]
loss: 2.231472 [ 6400/60000]
loss: 2.202953 [12800/60000]
loss: 2.199269 [19200/60000]
loss: 2.157749 [25600/60000]
loss: 2.128256 [32000/60000]
loss: 2.162331 [38400/60000]
loss: 2.106837 [44800/60000]
loss: 2.095415 [51200/60000]
loss: 2.103820 [57600/60000]
Test Error:
Accuracy: 41.8%, Avg loss: 2.075683
Epoch 4
-------------------------------
loss: 2.116516 [ 0/60000]
loss: 2.127561 [ 6400/60000]
loss: 2.063931 [12800/60000]
loss: 2.068631 [19200/60000]
loss: 2.028058 [25600/60000]
loss: 1.978367 [32000/60000]
loss: 2.039679 [38400/60000]
loss: 1.945373 [44800/60000]
loss: 1.913234 [51200/60000]
loss: 1.984692 [57600/60000]
Test Error:
Accuracy: 43.5%, Avg loss: 1.912075
Epoch 5
-------------------------------
loss: 1.963918 [ 0/60000]
loss: 1.978229 [ 6400/60000]
loss: 1.871736 [12800/60000]
loss: 1.907519 [19200/60000]
loss: 1.893454 [25600/60000]
loss: 1.814124 [32000/60000]
loss: 1.916281 [38400/60000]
loss: 1.786350 [44800/60000]
loss: 1.738751 [51200/60000]
loss: 1.888867 [57600/60000]
Test Error:
Accuracy: 47.7%, Avg loss: 1.770871
Done!모델 저장하기
모델을 저장하는 일반적인 방법은 (모델의 매개변수들을 포함하여) 내부 상태 사전(internal state dictionary)을 직렬화(serialize)하는 것이다.
| torch.save(model.state_dict(), "model.pth") print("Saved PyTorch Model State to model.pth") |
Saved PyTorch Model State to model.pth모델 불러오기
모델을 불러오는 과정에는 모델 구조를 다시 만들고 상태 사전을 모델에 불러오는 과정이 포함된다.
| load_model = NeuralNetwork() load_model.load_state_dict(torch.load("model.pth")) print(load_model) |
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)'AI' 카테고리의 다른 글
| 벡터 스토어와 RAG 실습 (0) | 2025.04.03 |
|---|---|
| 랭체인을 이용한 RAG (0) | 2025.04.01 |
| Deep Learning 텐서(Tensor) (0) | 2025.03.28 |
| Deep Learning 개론 (0) | 2025.03.28 |
| Agents Are Not Enough, Integration of Agentic AI with 6G Networks for Mission-CriticalApplications: Use-case and Challenges 논문 리뷰 (1) | 2025.03.12 |


