728x90
성능 최적화
- 모델의 복잡도와 과적합
- Early Stopping
- Dropout
모델의 복잡도와 과적합(Overfitting)
모델링의 목적
모델링의 목적
- 학습용 데이터에 있는 패턴으로, 그 외 데이터(모집단 전체)를 적절히 예측
- 학습한 패턴(모델)은,
- 학습용 데이터를 잘 설명할 뿐만 아니라
- 모집단의 다른 데이터(val, test)도 잘 예측해야 함
- 모델의 복잡도
- 너무 단순한 모델 : train, val 성능이 떨어짐
- 적절히 복잡한 모델 : 적절한 예측력
- 너무 복잡한 모델 : train 성능 높고, val 성능 떨어짐

Underfitting과 Overfitting

- 모델(알고리즘)마다 복잡도를 결정하는 요인이 있음.
과적합 Overfitting : 왜 문제가 될까?
- 모델이 복잡해 지면, 가짜 패턴(혹은 연관성)까지 학습하게 됨.
- 가짜 패턴
- 학습 데이터에만 존재하는 패턴
- 모집단 전체의 특성이 아님
- 학습 데이터 이외의 데이터 셋에서는 성능 저하
성능 최적화와 과적합의 관계
- 모델의 복잡도 : 학습용 데이터의 패턴을 반영하는 정도

우리가 목표로 잡아야하는 성능은 일반화 성능 : 학습용 데이터 에서만 성능이 좋은게 아니라 다른 데이터 에서도 그 성능이 유지 되는 것
적절한 모델은 어떻게 만들까?
- 적절한 복잡도 지점 찾기
- 알고리즘 (모델)마다 각각 복잡도 조절 방법이 있음
- 복잡도를 조금씩 조절해 가면서 (보통 하이터파라미터 조정)
- Train error와 Validation error 를 측정하고 비교 (관점은 Validation error)
- 이런 방법을 우리는 '하이퍼 파라미터 튜닝' 이라고 부름
- 하이퍼 파라미터 튜닝을 하게 되면 과적합을 예방하는 과정이 포함되어 있는 것
- 딥러닝에서 조절할 대상
- Epoch(전체 데이터를 몇번 학습할 것인지) 와 learning_rate
- 모델 구조 : hidden layer 수, node 수
- 미리 멈춤 : Early Stopping
- 임의 연결 끊기 : Dropout
- 가중치 규제하기 : Regularization(L1, L2)
딥러닝의 복잡도 : hidden layer 수, node 수

- 딥러닝 모델의 복잡도 혹은 규모와 관련된 수 : 파라미터(가중치) 수
- input feature 수, hidden layer 수, node 수와 관련 있음
- Conv layer인 경우, MaxPooling Layer를 거치면 데이터가 줄어들어 파라미터 수 감소
- 파라미터 수가 많을수록
- 복잡한 모델
- 연결이 많은 모델
- 파라미터가 아주 많은 언어 모델 -> Large Language Model
- 파라미터 수 확인
- torchsummary 라이브러리의 summary 함수 사용

학습
- Validation Accuracy 성능 측정

- Validation Accuracy 값, 학습 곡선에 포함

미리 멈춤 (Early Stopping)
- 반복 횟수(epoch)가 많으면 과적합 될 수 있음
- 항상 과적합이 발생하는 것은 아님
- 반복횟수가 증가할 수록 val error 가 줄어들다가 어느 순간부터 다시 증가할 수 있다.
- val error 가 더 이상 줄지 않으면 멈춰라 -> Early Stopping
- 일반적으로 train error는 계속 줄어듦

Early Stopping 코드 구현
- 절차
- for loop (epochs)
- if 현 epoch 의 val_error < 전 epoch 의 val_error best_error = 현 val_error
- else counter += 1
- if counter > p, 학습 종료 (p는 임계 값, 현 val error 가 best_error보다 p번 이상 높으면 학습 종료)

Best Model 저장하기
- Early Stopping
- 현 val error 가 best error보다 p번 (임계 값) 높으면 멈춰라.
- 최종 모델은 best 모델이 아니라, best 모델보다 p번 에러가 더 높아진 모델임.
- 이에 best error 일 때의 모델을 저장하기 위한 장치 필요.

- PyTorch 모델 저장
- 파이토치 모델의 확장자 : .pt
- torch.save() 함수

- 모델 로딩
- torch.load() 함수

임의로 연결 끊기 Dropout
연결을 임의로 끊는 Dropout
- Dropout
- 과적합을 줄이기 위해 사용되는 정규화 (regularization) 기법 중 하나
- 훈련 과정에서 신경망의 일부 뉴런을 임의로 비활성화 시킴으로써 모델을 강제로 과적합 방지
- 학습 시 적용 절차
- 학습 시, 랜덤하게 선택된 일부 뉴런을 제거
- 제거된 뉴런은 해당 배치에 대한 순전파 및 역전파 과정에서 비활성화
- 이를 통해 뉴런들 간의 복잡한 의존성을 줄여 줌
- 매 epochs마다 다른 부분 집합의 뉴런을 비활성화 -> 앙상블 효과

- Hidden Layer 다음에 Dropout 을 추가
- Dropout Rate
- 0.4 : hidden layer 의 노드 중 40% 를 임의로 제외시킴
- 보통 0.2 ~ 0.5 사이의 범위 지정
- 적절한 값은 조절하면서 찾아야 함 (하이퍼 파라미터)
- 경험에 의하면
- Feature 수 : 적을 경우 rate를 낮추고, 많을 경우 rate 를 높이기
- Layer 수 : 적을 경우 rate를 낮추고, 많을 경우 rate를 높이기
- Dropout 함수
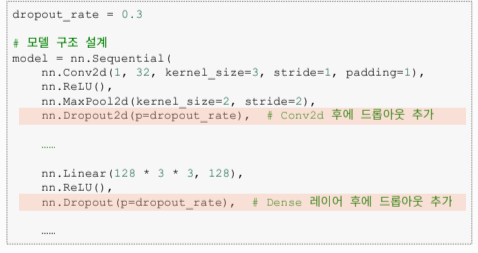
- Conv2d : Dropout2d()
- Linear : Dropout()
딥러닝 성능 최적화 접근법
- 1. 복잡한 모델을 설계
- 규제 방법으로 과적합 제한
- Early Stopping : 학습횟수 규제
- Dropoput : 임의 연결 끊기
- Regularization
Class 로 선언하기
- 모델 선언 방식

- init 부분 : 사용할 메소드를 정의하는 부분
- forward 메소드 안에서는 메소드 정의한 것을 사용을함


클래스 선언 방식 예 - CNN

init 안에 필요한 레이어드 구성 (왼쪽 코드와 동일하게 만들면됨)
forward 안에는 피드 포워드 과정으로 진행됨
요약

728x90
'AI' 카테고리의 다른 글
| 성능 최적화 및 클래스 선언 실습 (0) | 2025.03.06 |
|---|---|
| CNN 모델링 실습 (0) | 2025.03.05 |
| CNN 모델링 (0) | 2025.02.26 |
| 분류 모델링 실습 (0) | 2025.02.26 |
| 분류 모델링 (0) | 2025.02.25 |

