728x90
CNN 기초
- CNN 개념 이해
- CNN 구조
- 코드 이해
CNN 개념 이해
CNN 컨셉 - 영역
- 이 사진을 보고 어떻게 고양이인지 알 수 있나요?

귀, 눈, 코, 수염??
- 이 모든 것은 특정 부분(영역)에서 얻어낸 특징(feature)이다.
- 이러한 특징으로 부터 고양이(target)인지 알 수 있다.
CNN 컨셉 - 영역, 그리고 필터
- 고양이의 특정 부분을 잘 캐치해 내는 필터들을 만들고자 한다,
- 귀를 잘 캐치해내는 필터
- 귀 부분을 찾으면 숫자가 커지고
- 없으면 숫자가 거의 0에 가까워 지는
- 이동
- 왼쪽 위 끝에서 부터
- 오른쪽으로 몇 칸씩 움직이며 '귀'를 찾습니다.
- 오른쪽 끝까지 이동한 후에
- 왼쪽으로 돌아와 아래로 몇 칸 내려와서
- 다시 오른 쪽으로 이동한다.

CNN 컨셉 - 모델 학습
- CNN 학습 : 고양이를 잘 맞추는 필터 여러 개를 만드는 것이다.
- 이 설명은 이해를 돕기 위한 것이다.
- 실제로는 귀나 눈 등 우리가 이해하는 특징이 아닌,
- 우리가 이해할 순 없지만, 고양이를 찾는 데에 오차를 최소화하는 특징을 추출하는
- 필터를 만들어 내게 된다.
- 필터 = 특징추출기
- 예측
- 학습된 필터를 이용해 새로운 사진으로부터 특징을 추출하여
- 고양이 인지 아닌지 판별
- mnist 다중 분류 모델을 CNN으로 만들면서 그냥 따라 해보겠습니다.
CNN 구조
- 복잡해 보이지만 4가지만 기억하면 된다.

- 1. input_shape : 분석 단위인 이미지 한 장의 크기 (픽셀 사이즈, 채널 * 세로 * 가로)

- 2. Convolutional Layer : 필터로 지역적인 특성(feature)를 뽑는 과정.

- 3. Max pooling Layer : 뽑은 특징을 요약 (압축)

- 4. 펼쳐서 (Flatten), Dense Layer에 연결

CNN 코드 이해
nn.Conv2d
- Conv2d : 이미지 분석에 주로 사용
- 지역적(Local)특징을 추출
- 필터(커널)
- 2차원으로 이동하며 Feature Map 구성
- 입력(채널) 수 : 1, 출력(커널) 수 : 32
- kernel_size = 3 : 세로 3, 가로 3
- 필터(커널)
- 지역적(Local)특징을 추출

- 합성곱(Convolution)연산

- Stride : 몇 칸 씩 이동할 것인지 지정
- Stride = 1 가로, 세로 이동 칸 수
- Size 축소 5 X 5 -> 3 X 3
- Size를 유지하려면 padding 옵션 이용. (보통 stride =1로 지정함)


- Padding
- Size 유지되도록 이미지 둘레에 0으로 덧대기
- Input : 5 X 5 -> Output : 5 X 5
- padding = 1 -> 1칸 (픽셀) 덧대기

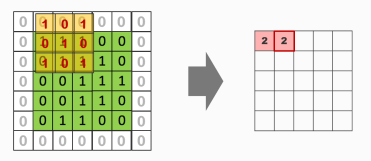
- 은닉층의 활성화 함수 : ReLU
nn.MaxPooling2d
- MaxPooling
- 목적 : 강조할 데이터만 남기고 크기 축소(채널내 가장 큰 값을 뽑아 정렬, 일반적으로 kernel_size 는 2로함)
- kernel_size = 2 : 풀링 크기 2 X 2
- stride = 2 : 2 칸 씩 이동
- 출력 크기
- Input Size / Pooling size (나머지는 버림)


- 연산자 // : 몫 계산 (예 : 7 // 2 = 3)
Multi-Layer

Flatten 과 Dense Layer
- CNN + MaxPooling Layer 로 특징을 추출한 후,
- 최종 예측 결과로 뽑기 위해서는
- 1. 값을 펼치고 (Flatten)
- 2. nn.Linear 로 연결해야 합니다.
- 주의 : 입력 데이터 크기는 이전 레이어의 출력 크기 (이전 페이지 참조)

CNN 구조와 코드 전체

직접 그림을 그려서 예측해보기
- 그림판에서 왼쪽, 펜/브러시 두께를 10px로 지정
- 숫자 하나 쓰고, 파일로 저장
- 이미지 파일 업로드 : 파일 탭 > 이미지파일 drag&drop
- cv2 : opencv, 굉장히 유명한 이미지 처리 라이브러리 이다.
- 데이터 전처리
- 1. 이미지 크기 맞추기
- 원본 이미지 100 * 100 을 학습할 때 크기 28 * 28 로 변환
- 1. 이미지 크기 맞추기
- 입력할 데이터셋 구조
- 2. 데이터 셋 구조 : (n, 1, 28, 28)
- 학습 시 데이터셋 구조와 동일해야 함
- 3. 스케일링 : 255로 나누기
- 4. 텐서로 변환
- 2. 데이터 셋 구조 : (n, 1, 28, 28)

- 예측
- 평가 모드 선언
- 그래디언트 계산하지 않게 하고
- 데이터를 사전 정의된 device에 할당
- 예측결과 계산
- 소프트맥스를 이용해 확률 값으로 변환
- 확률이 가장 큰 인덱스(여기서는 숫자) 찾기

요약

- 컬러 뒤 3은 R G B
728x90
'AI' 카테고리의 다른 글
| 성능 최적화 및 클래스 선언 (0) | 2025.03.05 |
|---|---|
| CNN 모델링 실습 (0) | 2025.03.05 |
| 분류 모델링 실습 (0) | 2025.02.26 |
| 분류 모델링 (0) | 2025.02.25 |
| 회귀 모델링 실습 (0) | 2025.02.24 |


