AI
분류 모델링
Astero
2025. 2. 25. 12:46
728x90
분류 모델링
- Hidden Layer 이해
- Binary Classification
- Multi-class Classification
Hidden Layer 이해
Hidden Layer 에서 무슨일이 일어나는가?
- 실제 Hidden Layer 의 각 노드가 어떤 (비즈니스) 의미인지 파악하는 것은 어렵다.
- 아래 학습할때는 이해를 돕기 위해 특별한 모델 구조를 구성했음
- 연결
- 모든 노드 간에 연결을 할 수 도 있지만 (Full Connected)
- 아래처럼 연결을 제어할 수도 있음 (Locally Connected)

- 학습
- 예측 값과 실제 값을 비교하며, loss funcion 으로 오차를 계산하고
- 오차를 줄이기 위해, 파라미터(가중치)를 업데이트 한다.

학습
- 드디어 오차를 최소화 하는 파라미터(가중치)를 찾았다.

- 학습이 완료된 후, Hidden Layer의 각 노드는 어떤 의미일까?

- 집값을 예측하는 데,
- Z1 = 내부 요인 점수와
- Z2 = 외부 요인 점수라고 볼 수 있지 않을까?

- 최종 집값을 예측하느데
- 내부요인과 외부요인에 가중치를 주고 최종 집값을 예측하게 될 것이다.
- 예를 들어, 내부 요인은 70%, 외부 요인은 30% 가중치를 준다면
- 집값 = 0.7 * 내부요인 + 0.3 * 외부요인
- 처음으로 돌아와서 Hidden Layer에서는 어떤 일이 일어났을까?
- 새로운 특징 (New Feature) 생성
- (mse)오차를 최소화 해주는 유익한 특징일 것이다.
- Hidden Layer에서는 기존 데이터가 새롭게 표현(Representaion)됨
- Feature Engineering 이 진행된 것입니다.
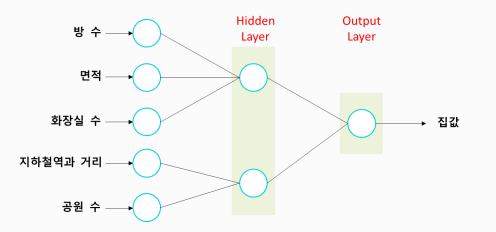
- 이를 Feature Representation 이라고 부른다,
- 그래서 Deep Learning을 R epresentation Learning 이라고 부르기도 한다.

Binary Classification
함수 (Function)
- 함수는
- 입력 값input 을 넣으면, 출력 값 output 을 줍니다.
- 입력 값을 x, 출력 값을 y로 표현합니다.
- 그러므로, x를 y로 변환 transgormation 시켜준다고 할 수 있습니다.

- 만약 다음과 같은 함수가 있다면
- f(x) = x^2
- 이렇게 변환시켜주는 기능을 한다.


이진분류의 출력층
- 아래 구조에서 Survived를 예측하기 위한 함수는 다음과 같이 만들어 진다.

- 그런데, 우리는 0, 1로 예측하고 싶다, 어떻게 하면 좋을까?

- 출력층의 결과를 0, 1로 변환해주는 함수가 필요
- 활성함수 : 시그모이드


활성화 함수 정리
- node의 결과를 변환시켜 주는 역할

분류 모델의 Loss Function
- 실제 값과 예측 값이 다음과 같다고 하자
- 우리는 이를 하나의 숫자(오차)로 평가해야 한다.

- y = 1 인 경우 오차를 다음과 같이 변환하고자 한다.
- ^y 가 1에 가까울수록 -> 오차는 0 에 가까워지도록
- ^y 가 0에 가까울수록 -> 오차는 무한대에 가까워지도록

- y = 0인 경우 오차를 다음과 같이 변환하고자 한다.
- ^y가 0에 가까울수록 -> 오차는 0에 가까워지도록
- ^y가 1에 가까울수록 -> 오차는 무한대에 가까워지도록

- 이 오차들의 평균
- Binary Cross Entropy
- PyTorch 제공함수 : nn.BCELoss

분류모델 평가
- 회귀와 다른 점
- 분류 모델 출력 ㅊ층의 활성화 함수(시그모이드)
- 예측 결과 0~1 사이 확률 값
- 분류 모델 출력 ㅊ층의 활성화 함수(시그모이드)
- 예측 결과에 대한 후속 처리
- 결과를 .5 기준으로 잘라서 1, 0으로 변환
- np.where(조건문, 참일 때 값, 거짓일 때 값)
- 결과를 .5 기준으로 잘라서 1, 0으로 변환

분류모델 평가 : Confusion Matrix
- 일반적으로 이진 분류일때,
- 우리의 관심사 = 1, 양성 Positive
- 그 외 = 0, 음성 Negative



- f1-score
- precision과 recall의 조화 평균
- 예) 갈 때 60km/h, 올 때 80km/h 로 주행 했을 때, 평균 속력은?

- macro avg : 산술평균
- support : 데이터 개수
- weighted avg : 가중 평균
Multi-Class Classification
다중 분류 모델의 출력층
- Node 수
- 다중분류 모델에서 Output Layer의 node 수는 y의 범주 수와 같다.

다중 분류에서 출력층의 노드의 수는 다중분류 클래스 수많큼임
- Softmax
- 각 Class 별 (output node)로 예측한 값을 , 하나의 확률 값으로 변환

다중 분류 모델의 Loss Function
소프트 맥스는 각각의 값을 전체 확률 값으로 변환하기 위해서 사용 이렇게 나온 결과를 오차를 계산하기 위해 써야하는데 오차를 계산하는 함수는 크로스 엔트로피 이다.
- Cross Entropy
- 각 범주별, 실제 값 범주에 대한 예측 값의 Log Loss

- nn.CrossEntropyLoss()
- 손실함수 내부에 SoftMax 연산이 포함됨 -> 모델의 출력층에 SoftMax 활성함수 추가할 필요 없음
다중 분류 모델의 평가
- 이진 분류와 다른 점
- 이진 분류는 예측 결과가 0 ~ 1 의 확률값 이에 np.where()로 0~1사이의 확률 값을 0.5를 기준으로 0과 1로 쪼갬
- 다중 분류 모델은 예측 한 다음 결과를 열어보면 각각에 대한 숫자가 나오고, 이 숫자를 softmax로 변환을 해줌, 변환해주면 0 1 2 각각에 대해 어떤 확률인지 계산됨, 즉 softmax로 변환해서 각각의 확률값으로 변환해주고 가장 큰 값에 가장 큰 확률에 인덱스를 뽑는 np.argmax 함수를 이용해서 인덱스를 뽑게됨 (아래 사진 및 글로 으로 절차가 정리되어 나와있음)
- 다중분류 모델에 엑티베이션 펑션을 사용하지 않듯이 원래는 softmax는 이론적으로는 필요한데 코딩할때는 쓰지않음, 로스트펑션인 크로스 엔트로피 로스트펑션 안에 softmax 연산이 포함되기 때문
- 모델 구조에는 softmax를 쓰지는 않음, 모델 다 만들고 예측시 그냥 숫자 3가지가 나오는데 확률 값으로 변환하기 위해 softmax 함수를 써서 변환하고 이중 확률 가장 높은 인덱스가 먼지를 찾는 단계가 추가됨
- 다중 분류 모델 출력 층
- 노드 수 : 다중 분류 클래스의 수와 동일
- 활성화 함수 사용하지 않음
- 원래는 softmax가 필요하지만, 오차 함수에 포함됨
- 다중 분류 모델 출력 층
- 예측결과에 대한 후속 처리
- 예측 결과를
- softmax로 변환->확률값 / nn.functional.softmax
- 그중 가장 큰 값의 인덱스로 변환 / .np.argmax()

Multi-Class Classification 추가 실슴 - MNIST
- 이미지를 2차원 구조로 모델링하기 : MNIST
- 손 글씨 이미지를 2차원 데이터셋으로 변환하여 다중 분류 모델링 수행

- 본 실습을 수행하기 위해서는 2차원 이미지 데이터를 1차원으로 펼치는 Flatten함수가 필요하다.
- Flatten 은 다음과 같은 작업을 수행한다.

오늘 배운 내용 요약

728x90