728x90
- 2017 구글이 제안한 Sequence-to-Sequence 모델의 하나
- Attention is all you need라는 논문에서 제안된 모델
- 기존의 seq2seq 구조인 Encoder-Decoder 방식을 따르면서도 논문 제목처럼 Attention 만으로 구현한 모델임
- RNN 모델을 사용하지 않고 Encoder-Decoder를 설계 했음에도 번역 등 성능에서 더 우수한 성능 보임
- 기존의 seq2seq 모델은 인코더-디코더 구조로 구성
- 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어 냄 → 이러한 구조는
- 인코더가 입력 시퀀스를 하나의 벡터(고정길이)로 압축하는 과정에서
- 입력 시퀀스의 정보가 일부 손실된다는 단점이 발생하였고
- 이를 보정하기 위해 어텐션(Attention) 모델이 사용됨
- RNN에서 사용한 순환방식을 사용하지 않고 순수하게 어텐션만 사용한 모델(중요하다 싶은 것만 사용)
- 기존에 사용되었던 RNN, LSTM, GRU 등은 점차 트랜스포머로 대체되기 시작
- GPT, BERT, T5 등과 같은 다양한 자연어 처리 모델에 트랜스포머 아키텍처가 적용됨
- 인코더
- 소스 시퀀스의 정보를 압축해 디코더로 보냄
- 디코더
- 인코더가 보내 준 소스 시퀀스의 정보를 받아서 타겟 시퀀스 생성
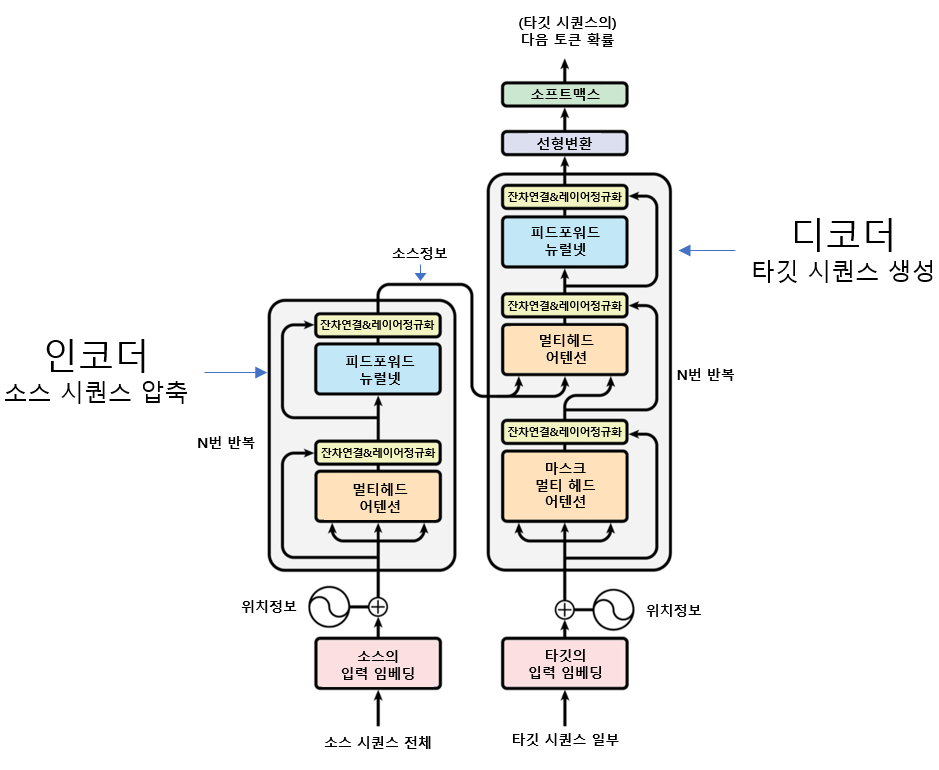
- 트랜스포머는 Sequence to Sequence 형태의 과제 수행에 특화된 모델.
- 임의의 시퀀스를 해당 시퀀스와 속성이 다른 시퀀스로 변환하는 작업이라면 꼭 기계 번역 이 아니라도 수행할 수 있음
- 예: 필리핀 앞바다의 한 달 치 기온 데이터 → 앞으로 1주일간 하루 단위로 태풍이 발생할지를 맞히는 과제(기온의 시퀀스 → 태풍발생 여부의 시퀀스)도 트랜스포머가 할 수 있는일임
-
- I를 예측하는 학습
- 인코더 입력: 어제, 카페, 갔었어, 거기, 사람, 많더라 → (소스 시퀀스 전체)
- 소스 시퀀스를 압축하여 디코더로 보내고
- 디코더 입력:
- 인코더에서 보내온 정보와 현재 디코더 입력을 모두 고려하여 토큰(I)를 예측
- 디코더의 최종 출력:
- 타깃 언어의 어휘 수만큼의 차원으로 구성된 벡터 → 이 벡터는 요소의 값이 모두 확률 값 (예: 타깃 언어의 어휘가 총 3만개라면 디코더 출력은 3만 차원의 벡터, 3만개 각각은 확률값)

-
- 트랜스포머의 학습 진행
- 인코더와 디코더의 입력이 주어졌을 때, 정답에 해당하는 단어의 확률값을 높이는 방식으로 학습함
- → 그림에서...
- 모델은 이번 시점의 정답인 I에 해당하는 확률은 높이고, 나머지 단어의 확률은 낮아지도록 모델 전체를 갱신

-
- went 를 예측할 차례 (y target으로 went가 들어감)
- 인코더 입력: 어제, 카페, 갔었어, 거기, 사람, 많더라 → (소스 시퀀스 전체)
- 디코더 입력:
- 특이사항
- 학습 중의 디코더 입력과 학습을 마친 후 모델을 실제 기계번역에 사용할 때(인퍼런스)의 디코더 입력이 다름
- 학습 중: 디코더 입력에 예측해야 할 단어(went) 이전의 정답 타깃 시퀀스(I)를 넣어줌
- 학습 후(인퍼런스 때): 현재 디코더 입력에 직전 디코딩 결과를 사용 (예: 인퍼런스 때 직전 디코더 출력이 I 대신 you가 나오면 다음 디코더 입력은 you)
- 특이사항

-
- ‘went’확률 높이기
- 학습 과정 중 인코더, 디코더의 입력이 아래 그림과 같으면...
- 모델은 이번 시점의 정답인 went에 해당하는 확률은 높이고
- 나머지 단어의 확률은 낮아지도록 모델 전체를 갱신함

-
- ‘to’ 예측하기
- 인코더 입력은 소스 시퀀스 전체
- 디코더 입력은 정답인 I went
- 인퍼런스 할 때, 디코더 입력은 직전 디코딩 결과
- 이번 시점의 정답인 to에 해당하는 확률은 높이고
- 나머지 단어의 확률은 낮아지도록 모델 전체를 갱신함

- 이상의 방식으로 말뭉치 전체를 반복해서 학습

- 트랜스포머는 블록 형태로 구성된 인코더, 디코더 수십개가 반복적으로 쌓여 있는 형태
- 이런 구조를 블록 또는 레이어라고 부름
- 인코더 블록: 3가지 요소로 구성
- 멀티 헤드 어텐션, 피드포워드 뉴럴 네트워크, 잔차 연결 & 레이어 정규화
- 디코더 블록: 인코더 블록이 변형된 형태
- 마스크 멀티 헤드 어텐션 추가됨(정답을 입력할때 넣는 것이므로 사실상 형태가 동일하다 볼 수 있다)

- 트랜스포머 구조에서 “멀티 헤드 어텐션”을 “셀프 어텐션“ 이라고 부름
- 어텐션
- 시퀀스 입력에 수행하는 기계학습 방법의 일종
- 시퀀스 요소 가운데 중요한 요소에 집중하고, 그렇지 않은 요소는 무시함으로써 태스크 수행 성능을 끌어올림
- 디코딩 시 소스언어의 단어 시퀀스 중에서 디코딩에 도움이 되는 단어 위주로 취사 선택(가장 중요한 것만 추려서), 번역 품질을 끌어올림
- 셀프 어텐션은 자신에게 수행하는 어텐션 기법 이다.
- 트랜스포머 경쟁력의 원천으로 평가된다.
- CNN: 합성곱 필터를 이용해 시퀀스의 지역적 특징을 잡아낼 수 있다
- 자연어는 기본적으로 시퀀스
- 특정 단어 기준으로 한 주변 문맥이 의미 형성에 중요한 역할을 수행
- 자연어 처리에 CNN이 사용되기 시작
- 합성곱 필터 크기를 넘어서는 문맥은 읽어 내기 어렵다
- 필터 크기가 3이면 4칸 이상 떨어져 있는 단어 사이의 의미는 잡아내기 어려움(이와 같은 문제로 셀프 어텐션이 사용됨)


- cafe에 대응하는 소스 언어의 단어: 카페 → 소스 시퀀스의 초반부에 등장
- cafe라는 단어를 디코딩 할 때, 카페를 반드시 참조
- 어텐션이 없는 단순 RNN이라면 워낙 초반에 입력된 단어라 잊었을 가능성이 크고, 이 때문에 번역 품질이 낮아 질 수 있다.
- 어텐션은 소스 시퀀스 전체 단어들과 타깃 시퀀스 단어 하나 사이를 연결하는데 사용. 셀프 어텐션은 입력 시퀀스 전체 단어들 사이를 연결

- 어텐션은 RNN 구조 위에서 동작하지만 셀프 어텐션은 RNN 없이 동작함
- 타깃 언어의 단어를 1개 생성할 때 어텐션은 1회 수행하지만, 셀프 어텐션은 인코더, 디코더 블록의 개수만큼 반복 수행
- 쿼리(Q), 키(K), 값(V)이 서로 영향을 주고 받으면서 문장의 의미 계산
- 각 단어 벡터는 블록 내에서 계산과정을 통해 Q, K, V로 변환
- 쿼리 단어 각각을 대상으로 모든 키 단어와 얼마나 유기적인 관계를 맺는지를 총합이 1인 확률 값으로 표현
- “카페”와 가장 관련이 높은 단어는 “거기(0.4)”

- 머신러닝에서 모델링 시에 사용자가 직접 설정해 주는 값
- 학습률 등 다양한 종류가 있음
- 하이퍼 파라미터의 정의 및 특성
- 모델 하이퍼파라미터는 모델 외부에 있고 데이터에서 값을 추정할 수 없는 구성
- 모델 매개 변수를 추정하는 데 도움이 되는 프로세스에 자주 사용
- 관련 전문가에 의해 지정
- 휴리스틱(전문가 경험)을 사용해 설정할 수 있다
- 주어진 예측 모델링 문제에 맞게 조정됨
- 모델 하이퍼파라미터는 모델 외부에 있고 데이터에서 값을 추정할 수 없는 구성
- 하이퍼 파라미터와 파라미터를 혼용해 사용하고 있는데 둘은 엄연히 다른 개념으로, 파라미터는 모델 내부에서 결정되는 매개변수 이고, 데이터로 부터 결정된다. 반면 하이퍼 파라미터는 모델 외부에서 사용자가 직접 지정하는 값이다.

- 인코더-디코더 구조
- seq2seq: 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time step)을 가지는 구조
- 트랜스포머: 인코더와 디코더라는 단위가 N개로 구성되는 구조

- 트랜스포머를 제안한 논문에서는 인코더와 디코더의 개수를 각각 6개 사용

- 트랜스포머의 동작 형태
- 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 구조
- 디코더는 seq2seq 구조처럼 시작 심볼 를 입력으로 받아 종료 심볼 가 나올 때까지 연산을 진행 → RNN은 사용되지 않지만 인코더-디코더의 구조는 유지되고 있다.

-트랜스포머의 입력
- RNN이 자연어 처리에서 유용했던 이유
- 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치 정보 (position information)를 가질 수 있었기 때문
- 트랜스포머의 경우
- 단어 입력을 순차적으로 받지 않음 -> 단어의 위치 정보를 알려줄 방법이 필요함
- 포지셔널 인코딩 적용
- 단어의 위치 정보를 얻기 위해
- 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용
- 입력되는 임베딩 벡터들은 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩의 값이 추가됨

- 임베딩 벡터에 포지셔널 인코딩값이 더해지는 과정

- 포지셔널 인코딩 값의 계산
- 트랜스포머는 위치 정보를 가진 값을 만들기 위해서 아래의 두 개의 함수를 사용

- (𝑑𝑚𝑜𝑑𝑒𝑙은 트랜스포머에서는 512)
- 사인, 코사인 함수의 그래프에서 값의 형태를 생각해볼 수 있다. 트랜스포머는 사인 함수와 코사인 함수의 값을 임베딩 벡터에 더해줌으로써 단어의 순서 정보를 추가한다.

- 𝑝𝑜𝑠 : 입력 문장에서의 임베딩 벡터의 위치
- 𝑖 : 임베딩 벡터 내의 차원의 인덱스
- 𝑑𝑚𝑜𝑑𝑒𝑙 : 트랜스포머의 모든 층의 출력 차원을 의미하는 트랜 스포머의 하이퍼 파라미터
- 짝수(pos, 2i) 인 경우에는 사인 함수의 값을 사용
- 홀수(pos, 2i+1) 인 경우에는 코사인 함수의 값을 사용
- 임베딩 벡터도 𝑑𝑚𝑜𝑑𝑒𝑙 의 차원을 가짐
- 위의 그림은 4차원의 예시를 들고 있으나 논문에서는 512차원을 사용함
- 포지셔널 인코딩 방법을 사용하면 순서 정보가 보존됨
- 각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으 로 들어가는 임베딩 벡터의 값이 달라짐
- 이에 따라 트랜스포머의 입력은 순서 정보가 고려된 임베딩 벡터가 됨
- 트랜스포머에서 사용되는 어텐션
- Encoder Self-Attention
- Masked Decoder Self-Attention
- Encoder-Decoder Attention


- 인코더의 구조
- 트랜스 포머는 하이퍼 파라미터인 num_layers(6)개의 인코더 층이 쌓여서 구성됨
- 하나의 인코더 층은 크게 총 2개의 서브층으로 구분
- 셀프 어텐션 (= 멀티 헤드 셀프 어텐션)
- 피드 포워드 신경망 (= 포지션 와이즈 피드 포워드 신경망)

- 기존 어텐션 개념
- 어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 계산
- 계산된 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영
- 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴

- 셀프 어텐션(self-attention)
- 어텐션을 자기 자신에게 수행한다는 의미
- 어텐션을 사용할 경우의 Q, K, V의 정의

- t 시점: 계속 변화하면서 반복적으로 쿼리를 수행함을 표현
- → 전체 시점에 대해서 일반화한다면

- 기존 어텐션: 디코더 셀의 은닉 상태가 Q, 인코더 셀의 은닉 상태가 K → Q와 K가 서로 다른 값
- 셀프 어텐션: Q, K, V가 전부 동일

- 셀프 어텐션을 통해 얻을 수 있는 대표적인 효과

- Q, K, V 벡터 얻기
- 셀프 어텐션은 입력 문장의 단어 벡터들을 가지고 수행한다 → 인코더의 초기 입력인 𝑑𝑚𝑜𝑑𝑒𝑙 의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는 것이 아니라 각 단어 벡터들로부터 Q벡터, K벡터, V벡터를 얻는 작업 수행
- Q, K, V들은 초기 입력인 𝑑𝑚𝑜𝑑𝑒𝑙 의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가짐
- 작은 차원의 크기는 하이퍼파라미터인 num_heads로 인해 결정

- 예문 중 student라는 단어 벡터를 Q, K, V의 벡터로 변환하는 과정




- 굳이 각 Q벡터마다 따로 연산할 필요가 있을까? → 행렬 연산으로 일괄 처리하기


- 행렬연산에 사용된 행렬의 크기를 정리하면

- 멀티 헤드 어텐션
- 앞서 배운 어텐션에서는 𝑑𝑚𝑜𝑑𝑒𝑙 의 차원을 가진 단어 벡터를 → num_heads로 나눈 차원을 가지는 Q, K, V벡터 로 바꾸고 어텐션을 수행
- 왜 𝑑𝑚𝑜𝑑𝑒𝑙 의 차원을 가진 단어 벡터를 가지고 어텐션을 하지 않고 차원을 축소시킨 벡터로 어텐션을 수행하였는가?

- 어텐셜을 병렬로 했을때 얻을 수 있는 효과
- 어텐션을 병렬로 수행하여 다른 시각으로 정보들을 수집하겠다는 것

- 병렬 어텐션 수행 후, 모든 어텐션 헤드를 연결(concatenate)
- → 모두 연결된 어텐션 헤드 행렬의 크기는 (𝑠𝑒𝑞_𝑙𝑒𝑛, 𝑑𝑚𝑜𝑑𝑒𝑙 )

- 어텐션 헤드를 모두 연결한 행렬에 또 다른 가중치 행렬 𝑊^𝑜 을 곱하기 → 이 결과 행렬이 멀티-헤드 어텐션의 최종 결과물임
- 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 크기 (𝑠𝑒𝑞_𝑙𝑒𝑛, 𝑑𝑚𝑜𝑑𝑒𝑙 ) 와 동일함 → 인코더의 입력으로 들어왔던 행렬의 크기가 아직 유지되고 있음

- 패딩 마스크 (Padding Mask)
- 가 포함된 입력 문장의 셀프 어텐션

- 어텐션을 수행하고 어텐션 스코어 행렬을 얻는 과정
- 의 경우에는 실질적인 의미를 가진 단어가 아니므로
- → 트랜스포머에서는 Key의 경우에 토큰이 존재한다면 이에 대해서는 유사도를 구하지 않도록 마스킹 (Masking)을 적용함
- 마스킹: 어텐션에서 제외하기 위해 값을 가린다는 의미
- 어텐션 스코어 행렬에서
- 행에 해당하는 문장은 Query
- 열에 해당하는 문장은 Key
- Key에 가 있는 경우에는 해당 열 전체를 마스킹
- 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수 값을 넣어주는 것
- 매우 작은 음수 값이라는 것은 -1,000,000,000과 같은 -무한대에 가까운 수라는 의미

- 현재 어텐션 스코어 함수는 소프트맥스 함수를 지나지 않은 상태
- 어텐션 스코어 함수는 소프트맥스 함수를 지나고, 그 후 Value 행렬과 곱하게 됨
- 현재 마스킹 위치에 매우 작은 음수 값이 들어가 있으므로
- 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0이 됨
- → 단어 간 유사도를 구하는 일에 토큰이 반영되지 않게 됨
- 어텐션 스코어 함수가 소프트 맥스 함수를 지닌 후
- 각 행의 어텐셜 가중치의 총 합은 1
- 단어 의 경우에는 0이 되어 어떤 유의미한 값을 가지지 않음

- 인코더와 디코더에서 공통적으로 가지고 있는 서브층이며 완전 FFNN(Fully-connected FFNN)
- 포지션 와이즈 FFNN의 수식:


- 잔차 연결이란?
- 블록이나 레이어 계산을 건너뛰는 경로를 하나 두는 것
- 구현
- 입력을 𝑥, 계산 대상 블록을 𝐹라고 할 때
- 잔차 연결은 𝐹(𝑥) + 𝑥로 간단히 실현
- 효과
- 동일한 블록 계산이 계속 반복될 때, 모델이 다양한 관점에서 블록 계산을 수행할 수 있도록 한다

- 잔차연결을 두지 않았을 때와 비교

- 잔차연결을 두지 않았을 때는 𝑓1 , 𝑓2 , 𝑓3 을 연속으로 수행하는 경로 한 가지만 존재
- 잔차 연결을 블록마다 설정해 둠으로써 모두 8가지의 새로운 경로가 생김 → 모델이 다양한 관점에서 블록 계산을 수행하게 됨
- 잔차연결의 필요성 및 효과
- 딥러닝 모델
- 레이어가 많아지면
- 모델을 업데이트하기 위한 신호(그래디언트)가 전달되는 경로가 길어지기 때문
- 학습이 어려워지는 경향이 있음
- 잔차연결의 도입은 모델 중간에 블록을 건너뛰는 경로를 설정함으로써 학습을 용이하게 하는 효과까지얻을 수 있음
- 미니 배치의 인스턴스(x)별로 평균을 빼 주고, 표준편차로 나누어서 정규화(normalization)을 수행하는 기법

- 효과: 레이어 정규화를 수행하면 학습이 안정되고 속도가 빨라짐
- 𝜸와 𝜷는 왜 1과 0으로 초기화 하는가?
- 1을 곱하고 마지막으로 0을 더해준다는 이야기 -> 학습 외에는 인워적인 병경을 주지 않는다.
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층이며 완전 FFNN(Fully-connected FFNN)
- 포지션 와이즈 FFNN의 수식:

- 𝑥: 멀티 헤드 어텐션의 결과로 나온 (𝑠𝑒𝑞_𝑙𝑒𝑛, 𝑑𝑚𝑜𝑑𝑒𝑙 )의
- 크기를 가지는 행렬



- 잔차 연결(Residual connection)과 층 정규화(Layer Normalization)
- 트랜스포머에서는 인코더의 두 개의 서브층에 추가적으로 Add & Norm을 적용
- Add : 잔차 연결(residual connection)
- Norm: 층 정규화(layer normalization)
- 트랜스포머에서는 인코더의 두 개의 서브층에 추가적으로 Add & Norm을 적용

- 서브층의 입력과 출력을 더하는 것
- 트랜스포머에서 서브층의 입력과 출력은 동일한 차원을 갖고 있으므로, 서브층의 입력과 서브층의 출력은 덧셈 연산이 가능
- 앞 페이지의인코더 그림에서 각 화살표가 서브층의 입력에서 출력으로 향하도록 그려졌던 이유
- 잔차 연결은 컴퓨터 비전 분야에서 주로 사용되는, 모델의 학습을 돕는 기법

- 입력 𝑥와 𝑥에 대한 어떤 함수 𝐹(𝑥)의 값을 더한 함수 𝐻(𝑥)의 구조 어떤 함수 𝐹(𝑥)가 트랜스포머에서는 서브층에 해당함
- 서브층이 멀티 헤드 어텐션인 경우, 잔차 연결 연산 수식

- 멀티 헤드 어텐션의 입력과 멀티 헤드 어텐션의 결과가 더해지는 과정

- 층 정규화(Layer Normalization)
- 잔차 연결을 거친 결과는 이어서 층 정규화 과정을 거치게 됨
- 잔차 연결의 입력을 𝑥, 잔차 연결과 층 정규화 두 가지 연산을 모두 수행한 후의 결과 행렬을 𝐿𝑁이라고 하였을 때, 잔차 연 결 후 층 정규화 연산을 수식으로 표현하면

- 층 정규화: 텐서의 마지막 차원에 대해서 평균과 분산을 구하고, 이를 가지고 어떤 수식을 통해 값을 정규화하여 학습을 돕는 작업
- 텐서의 마지막 차원: 트랜스포머에서는 𝑑𝑚𝑜𝑑𝑒𝑙 차원



- 인코더 → 디코더
- 인코더는 총 num_layers 만큼의 층 연산을 순차적으로 한 후
- 마지막 층의 인코더의 출력을 디코더에게 전달
- 디코더도 num_layers 만큼의 연산을 수행
- 매 연산마다 인코더가 보낸 출력을 각 디코더 층 연산에 사용

- 디코더의 서브층 (1): 마스크드 멀티헤드 셀프 어텐션
- 셀프 어텐션 + 룩-어헤드 마스크
- 디코더도 인코더와 동일하게 임베딩 층과 포지셔널
- 인코딩을 거친 후의 문장 행렬이 입력
- 디코더는 학습 과정에서 번역할 문장에 해당되는
- je suis étudiant의 문장 행렬을 한 번에 입력받음
- → 입력된 문장 행렬로부터 각 시점의 단어를 예측 하도록 훈련됨

- 트랜스포머는 교사 강요(Teacher Forcing)을 사용하여 훈련을 수행
- 교사 강요(Teacher Forcing)
- 트랜스포머 아키텍처는 seq2seq를 기반으로 하고 있으며, seq2seq는 RNN을 기반으로 함
- 현재 시점의 디코더 셀의 입력은 오직 이전 디코더 셀의 출력을 입력으로 받는다고 설명하였는데 decoder_input이 왜 필요할까?
- 이전 시점의 디코더 셀의 예측이 틀렸는데 이를 현재 시점의 디코더 셀의 입력으로 사용하면
- → 현재 시점의 디코더 셀의 예측도 잘못될 가능성이 높고
- → 이는 연쇄 작용으로 디코더 전체의 예측을 어렵게 만들며
- → 이런 상황이 반복되면 훈련 시간이 길어짐
- 이전 시점의 디코더 셀의 예측값 대신 실제 값을 현재 시점의 디코더 셀의 입력으로 사용함으로써 이러한 상황을 회피 하는 방법 → 교사 강요(Teacher Forcing)
- 문제점
- seq2seq의 디코더에 사용되는 RNN 계열의 신경망은
- → 입력 단어를 매 시점마다 순차적으로 입력 받으므로
- → 다음 단어 예측에 현재 시점을 포함한 이전 시점에 입력된 단어들만 참고할 수 있음
- 트랜스포머는
- → 문장 행렬로 입력을 한 번에 받으므로
- → 현재 시점의 단어를 예측하고자 할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생
- 트랜스포머의 디코더에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 룩-어헤 드 마스크(look-ahead mask, 미리보기에 대한 마스크)를 도입해서 사용한다.
- 디코더의 첫번째 서브층(멀티 헤드 셀프 어텐션)에서 이루어짐
- 멀티 헤드 셀프 어텐션 층
- 인코더의 첫번째 서브층인 멀티 헤드 셀프 어텐션 층과 동일한 연산을 수행 하는데 다른 점: 어텐션 스코어 행렬에서 마스킹을 적용한다는 점만 다름

- 룩-어헤드 마스크를 적용한 어텐션 스코어 행렬 계산

트랜스포머 아키텍처에 존재하는 어텐션
- 인코더의 셀프 어텐션
- 패딩 마스크를 전달
- 디코더의 마스크드 셀프 어텐션(첫번째 서브층)
- 룩-어헤드 마스크를 전달 + 패딩 마스크 (룩-어헤드 마스크를 한다고 해서 패딩 마스크가 불필요한 것은 아님)
- 디코더의 인코더-디코더 어텐션(두번째 서브층)
- 패딩 마스크를 전달
- 디코더의 서브층 (2): 인코더-디코더 어텐션
- 셀프 어텐션이 아님
- Query는 디코더 행렬, Key와 Value는 인코더 행렬이기 때문

- 그 외에 멀티 헤드 어텐션을 수행하는 과정은 다른 어텐션들과 동일함
https://github.com/Astero0803/Machine-Learning-Frameworks-/tree/main/tensorflow
Machine-Learning-Frameworks-/tensorflow at main · Astero0803/Machine-Learning-Frameworks-
Contribute to Astero0803/Machine-Learning-Frameworks- development by creating an account on GitHub.
github.com
- 이론 정리 후 Attention Model과 Transformer 실습을 진행함
- 해당 깃허브에서
- 2024_10_14_Attention_Model.ipynb
- 2024_10_14_Transformer.ipynb
- 이 두 파일 참조
728x90
'AI' 카테고리의 다른 글
| # 24.10.15_ ollama 로컬에서 사용 (0) | 2024.10.15 |
|---|---|
| # 24.10.15_ 사전학습 모델 + GPT + BERT모델 (6) | 2024.10.15 |
| # 24.10.11_언어모델의 이해 + Seq2Seq모델 + Attention 모델 (4) | 2024.10.11 |
| # 24.10.10_CBOW 임베딩 실습 + Skip-gram 임베딩 (2) | 2024.10.10 |
| # 24.10.08_전처리:단어의 표현 + 임베딩 (5) | 2024.10.08 |



