728x90
YOLO(You Only Look Once) 개요
-
- CNN은 너무 많은 연산을 요함으로 매우 처리 속도가 느림
-
- CNN 처리 이전에 인식하기 원하는 물체가 있을 가능성이 높은 후보 영역(적은 범위 영역)을 선택해 선택 영역에만 CNN을 적용해 성능 향상 효과를 보겠다는 것
-
- 이미지 입력
-
- 후보 영역 추출
- 딥러닝 영역이 아닌 데이터 정규화 영역에 가까움(CNN 내부의 LCN과 비슷한 개념)
- 후보영역 추출방법의 개선으로 Fast-RCNN/Faster-RCNN 모델 등장함
-
- CNN 특징 계산
-
- 영역 분류
- CNN < R-CNN < Fast-RCNN < Faster-RCNN

- 제안하는 후보 영역의 수가 너무 많음
- 후보 영역의 제안 과정에서의 부하가 큼
- 기존에 경계박스 치는 방법은 Proposal 방식
- Proposal 방식

- Grid 방식
- 영역 제안을 위한 부하가 거희 없음
- Yolo 방식
- Grid 방식을 더욱 발전시켜서 사용
- Grid 방식 선택 이유는
- 후보 영역 제안 개수가 적고
- 실시간성 확보가 용이함
- 찾고자 하는 물체(객체)가 있을 것 같은 후보영역을 제안한다 하는데
- 저렇게 박스를 제안할 때, 무슨 방법으로 박스 내부 물체가 있을 것이라 판단하고 선택할까?
- 박스 내부 물체가 있다고 어떻게 보장할까?
- 이것에 대답은 보장 못한다는 것이다(그냥 적당히 여러가지 정보, 기준을 잡고… 그냥 제안함 (영상의 Edge 정보, 임의의 박스 등등))
- 말 그대로 영상 1번만 읽음
- 최종 출력단에 경계박스 검색과 클래스 분류를 동시에 수행함(이로인해 속도가 빠름)
- 하나의 네트워크가 동시에 특징 추출, 경계박스 만들기, 클래스 분류를 다 진행함(이에 구조가 간단하고 빠름)
-
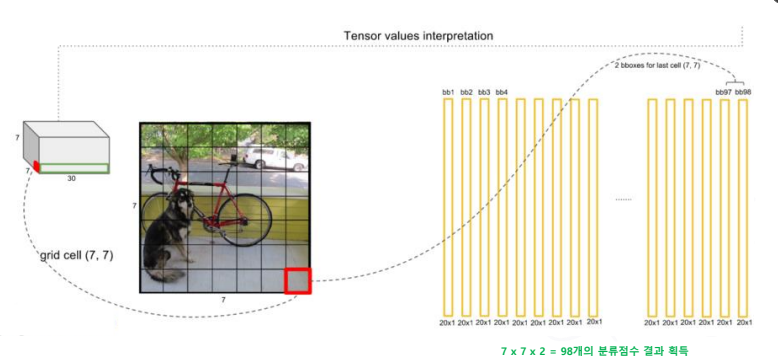
- 최종 결과에 무엇이 들어있을까?

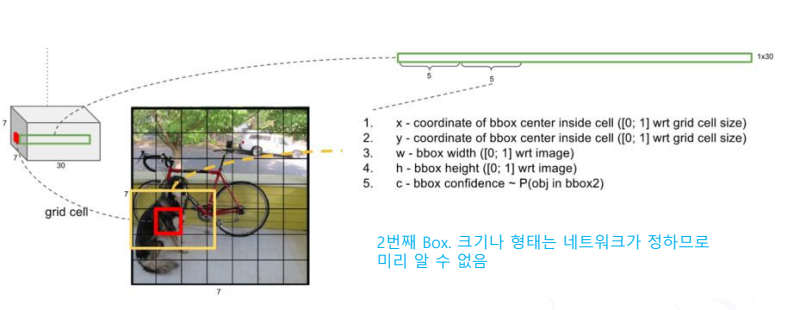
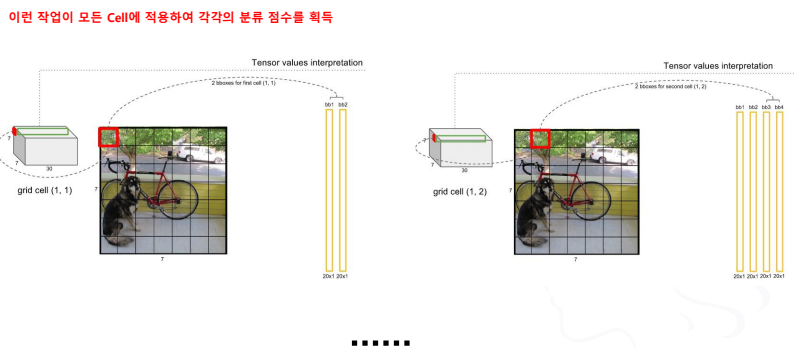

- 최종 결과에 무엇이 들어있을까?


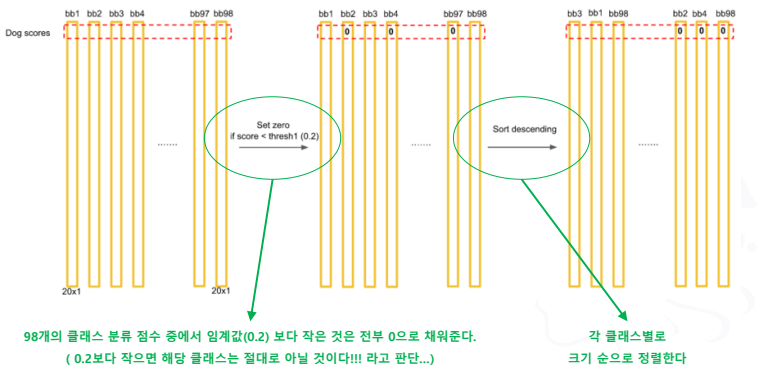
- 제일 가능성이 높은 것만 남기고 지우는데
- 강아지 2마리가 있으면?
- 위치가 겹치지 않고 동일한 클래스로 분류되면 큰 문제는 없다
- 비슷한 위치에 동일한 클래스들이 모여 있으면?
- 2마리 까지만 인식하게 됨(경계 Box가 2개 임으로)
- 점차 개선되고 있는 중
- 강아지 2마리가 있으면?

- 딥러닝에서 가장 중요한 것은 데이터이다. 그중에서도 학습을 위한 데이터가 가장 중요하다
- 같은 계열의 목적을 가진 모델이라면, 코드 변형 없이 데이터만 교체해 서로 다른 분야에 적용할 수 있다.
- CNN 비롯 영상 인식, 분류 등 목적으로 하는 딥러닝 모델은 학습의 결과가 옳은지, 그른지 확인할 수 있도록 각각의 영역을 구분하고 표시를 해두는데 이 작업 과정이 라벨링 작업 과정이다.
- 실력/기술이 없어서 못하는 것이 아니라 해 보지 않아서 몰라서 못하는 것이다.
- 데이터가 없는 점 이것이 가장 큰 문제이다 (데이터를 정리하는데 있어서 많은 기회비용이 요구됨)
- 시간의 순서대로 일정의 주기에 따라 측정, 저장된 데이터
- 데이터를 기반으로 한 예측 분야에 가장 많이 활용되고 있다.(분류보다는 예측에 많이 이용)
- 각혹 장애 검출에도 활용 가능하다(장애 검출도 결국 데이터 기반 예측임)
- 입력 데이터를 순서대로 살펴보면 조금씩 어긋나는 데이터가 발견됨
- 어긋나는 데이터의 범위가 특정 기준을 벗어나는 시점이 장애 발생 시점임
- 데이터의 변동을 기반으로 분석, 예측한 결과를 장애 검출, 장애 예측으로 표현하는것 뿐이다.
- 시계열 데이터는 시간에 따른 변화를 보고 패턴을 분석하여 이후에 어떤 데이터를 얻을 것인지 예측하는 것이 가장 큰 목적이자 활용 분야이다.
- 시계열 데이터는 어떤영향을 주고 받으면서 구성되는가?
- 시간의 흐름에 따른 데이터는 주변 환경과 특정 이벤트로부터 많은 영향을 받음(기상(날씨), 주식(주가))
- 단순히 데이터의 변화 패턴을 분석하는 것만으로는 예측이 어렵다
- 또한 어떤 값과 어떤 변수를 중심으로 분석하는가에 따라서도 큰 성능변화, 결과의 차이가 발생한다.
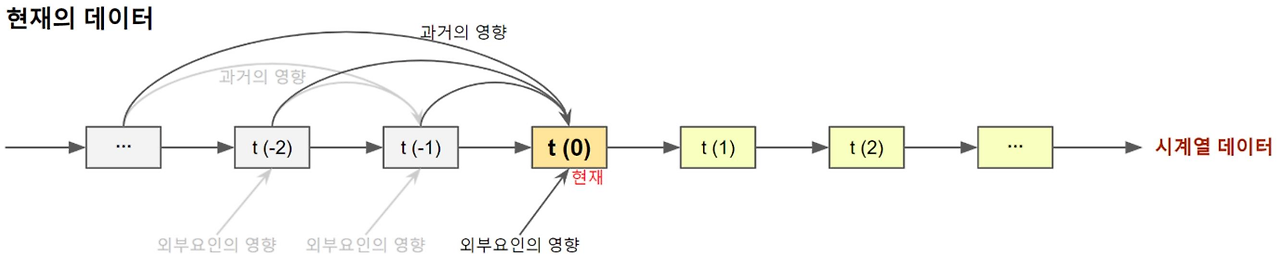
- 시계열 데이터를 이용한 예측은 어떤 개념인가?
- 현재(t(0))의 데이터는 과거 (t(-m)~t(-1))의 데이터가 누적된 결과이다.
- 가장 가까운 미래(t(1))의 데이터는 과거와 현재 (t(-m)~t(-1))의 데이터가 누적된 결과이다.
- 미래 (t(n))의 데이터는 (t(-m)~t(0)~t(n-1))의 데이터가 누적된 결과이고,
- 여기에 각 시점에서 적용되는 특정이벤트(외부요인)의 반영으로 예측된다.

- 모델 제안의 1단계
- 시계열 데이터란 시간의 순서대로 일정한 주기에 따라 측정, 저장된 데이터
- 과거 데이터가 현재 미래 데이터에 영향을 미침
- 과거 데이터를 저장, 참조할 수 있는 메모리 효과를 가진 모델이 필요함
- 시계열 데이터란 시간의 순서대로 일정한 주기에 따라 측정, 저장된 데이터
- 모델 제안의 2단계
- 현재의 데이터를 확인하기 위하여 과거의 데이터를 순차적으로 살펴보고
- t(1) 미래의 데이터를 확인하기 위하여 과거+현재의 데이터를 순차적으로
- t(n) 미래의 데이터를 확인하기 위하여
- 알고자 하는 시점의 데이터를 기준으로 과거의 데이터를 순서대로 확인 반복
- 즉, 동일한 과정, 모델이 계속적으로 반복되는 순환 과정을 가진 모델 필요
- 순환신경망 (RNN, Recurrent Neural Network) 제안됨
- 기존 신경망은 Feed Forward 방식 -> 데이터 처리 흐름이 한 방향(단방향)이다.

- 한 방향으로만 데이터 처리 하므로 시계열 데이터 처리가 어려움
- 시계열 데이터는 신경망 학습 완료 이후 실제 사용 도중에 지속적으로 과거 데이터를 참조및 활용해야함
- 학습 과정에서 시계열 데이터 성질, 패턴을 제대로 학습하기 어려움
- 이 단점으로 인해 순환 신경망이 등장한 것이다.
- 전체 네트워크 안에서 순환적으로 데이터를 처리하는 신경망 모델
- 과거의 데이터를 끊임없이 참조하여 현재의 데이터를 학습하는 모델
- 시간의 흐름에 따라 과거의 데이터의 특징과 패턴을 반영하여 현재의 데이터를 학습하는 모델
- 순차열, 즉 순서가 있는 일련의 값을 처리하는 것에 특화된 모델
- 순환 처리를 하기 위해서는 닫힌 경로(=순환하는 경로)가 필수
- 경로가 닫혀 있기 때문에 → 데이터가 순환하고, 데이터의 저장이 가능함
- 순환하기 때문에 → 끊임없이 데이터가 갱신됨
- RNN의 기본 단위 : RNN 계층
- 순환경로 포함
- 계속적 참조 반영
- 과거 정보를 기억

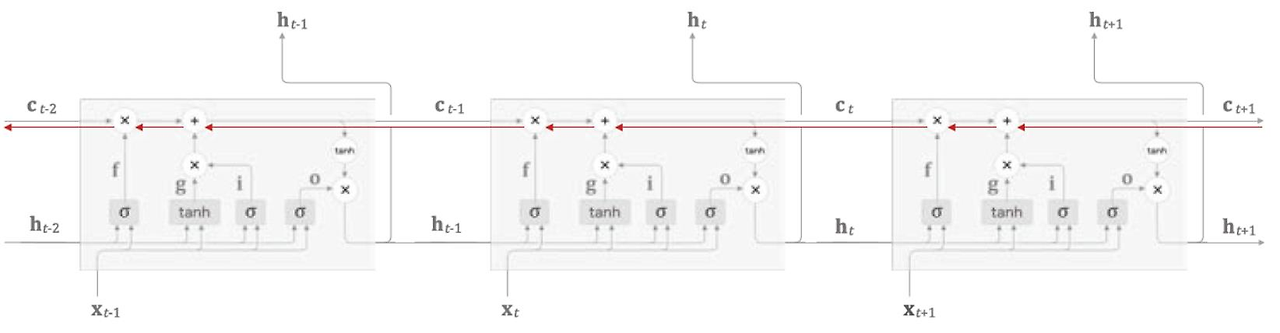
- 순환 구조 펼치면 아래와 같다
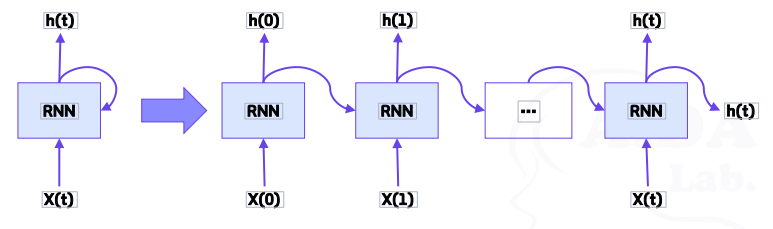
- 데이터는 시간이 흐르는 방향으로 나열(인덱스 T는 시간이 아니라 시각)
- 각 시각의 RNN 계층은 그 계층으로의 입력과 1개 전의 RNN 계층으로부터의 출력을 입력으로 받음
- 두 개의 입력을 기반으로 현 시각의 출력을 계산함
- 각 RNN 계층에서의 출력 계산에는 기존 신경망과 동일하게 경로 별 가중치, 편향 값이 포함됨


- RNN 계층은 가로로 펼쳐 놓은 신경망과 동일하다 가정할 수 있음
- 학습 방법도 동일하게 적용 가능(오류 역 전파 장식) -> BPTT방법

- 긴 시계열 데이터 학습시, 시계열 데이터의 시간 크기가 커질수록 BPTT가 소비하는 컴퓨팅 자원이 비례해서 증가, 시간의 크기가 커질수록 역 전파 시의 비율 조정을 위한 기울기가 불안정
- BPTT를 이용하여 기울기를 구할 때, 매 시각의 RNN 계층의 중간 데이터를 메모리에 유지해 두어야 함 → 시계열 데이터가 길어질 수록 계산 량 및 메모리의 사용량이 증가함
- 이를 개선하기 위해 나온것이 Truncated BPTT 기법
- 시간축의 방향으로 길어진 신경망을 적당한 지점에서 잘라내어 여러 개의 작은 신경망으로 만듦
- 잘라낸 작은 신경망 각각에서 BPTT를 수행함
- 신경망 잘래낼 때 역전파의 연결만 절당해야함(순전파 연결은 반드시 유지해야함)
- 순전파의 연결이 사라지게 되는 순간 네트워크 자체가 성립되어지지 않음
- 역전파가 연결된 RNN 계층의 모임을 블록이라 하고 다른 블로과 구분하여 처리함
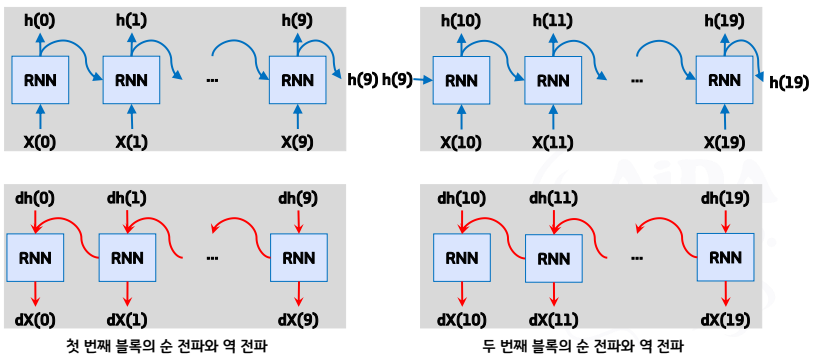
- 시계열 데이터의 학습에서 장기 의존 관계의 학습이 어렵다.
- BPTT에서 기울기 소실 또는 기울기 폭발이 발생
- 기울기 소실: 역 전파 처리 시 기울기 값이 점점 작아지다가 사라지는 현상
- 기울기 폭발: 역 전파 처리시 기울기 값이 점점 커지다가 수직에 가까워지는 현상
- 게이트 구조를 적용해 개선이 가능하다.
- 기본적인 RNN 모델을 개선한 다양한 RNN 모델이 존재
- 게이트가 추가된 RNN 모델
- 게이트라는 구조를 활용하여 시계열 데이터의 장기 의존 관계를 학습할 수 있는 모델
- 게이트를 통하여 입력 및 출력의 상태(범위)를 제어함
- 데이터 기억을 위한 메모리 셀을 추가한 형태이며 데이터의 기억 여부, 상태도 제어함
- LSTM (Long-Short Term Memory networks)
- RNN의 장기 의존성 문제를 해결할 뿐만 아니라 학습 또한 빠르게 수렴함
- GRU (Gated Recurrent Unit)
- LSTM의 간소화된 버전이라고 볼 수 있음
- RNN 모델의 주 사용 분야
- 기상 데이터 분석 및 예측, 주가 정보 예측(시계열 데이터)
- 자연어 처리, 번역, 언어 모델링 등 (순차열 데이터)
- Recurrent Neural Network(순환 신경망)과 Recursive Neural Network(재귀 신경망)을 같은 것이라고 설명하는 경우가 많음
- 순환 신경망과 재귀 신경망은 다른 모델이다. (구현한 방식이 다름)
- 재귀 신경망은 순환 신경망의 또 다른 일반화 버전이다.
- 순환 신경망은 체인 형태의 계산 그래프를 사용
- 재귀 신경망은 트리 형태의 계산 그래프를 사용
- 일반적으로 말하는 RNN은 순환 신경망을 의미한다.
- RNN의 문제점을 해결하기 위해 나온 모델
- 기울기 폭발, 소실 문제는 왜 발생하는가?
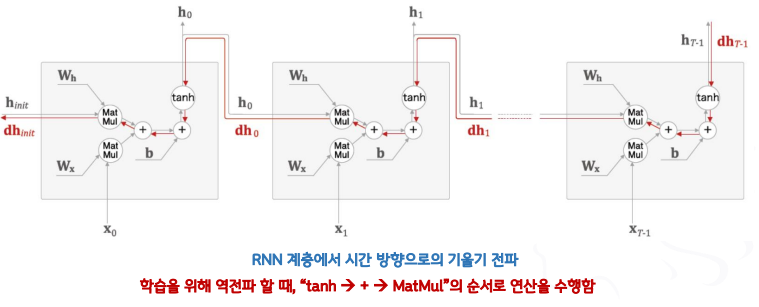
- 역전파 할 때, “tanh → + → MatMul”의 순서로 연산을 수행함
- “+” : 그냥 기울기의 정보를 전달할 뿐 기울기의 크기가 바뀌지 않음

- “+” : 그냥 기울기의 정보를 전달할 뿐 기울기의 크기가 바뀌지 않음
- “MatMul” : 𝒕𝒂𝒏𝒉(𝒙) 를 무시하고 “MatMul”만 집중해서 보면



- 기울기 폭발의 대책
- 기울기 클리핑(Gradients Clipping)
- 신경망에서 사용되는 모든 매개변수에 대한 기울기를 하나로 처리한다고 가정 ( ^𝑔 로 표시)
- 기울기의 L2-Norm 이 임계값(Threshold)을 초과하면 두 번째 줄의 수식과 같이 기울기를 수정
- 간단한 알고리즘이지만 많은 경우에 잘 작동함
- 기울기 클리핑(Gradients Clipping)

- 기울기 소실에 대책
- 간단한 방법으로는 대책을 찾을 수 없음(RNN 모델의 근본부터 뜯어고쳐야함)
- "기울기 소실이 일어나지 않도록 그 값을 직접 제어해 주겠다"라는 아이디어
- 제어를 위한 Gate 추가
- 다양한 알고리즘이 등장했으며 그 중 대표 알고리음이 LSTM, GRU이다.
- RNN과 LSTM의 구조 비교

- LSTM 계층의 인터페이스에는 c 라는 경로가 있다!
- c : Cell 또는 Memory Cell
- Memory Cell 특징
- 데이터를 자기 자신으로만(LSTM 계층 내에서만) 주고 받음
- → LSTM 계층 내에서만 완결되고, 다른 계층으로는 출력하지 않음
- Memory Cell 𝒄t 에는 시각 𝒕 에서의 LSTM의 기억을 저장함
- 과거로부터 시각 𝑡 까지에 필요한 모든 정보가 저장되어 있다고 가정함
- 또는 그렇게 저장되도록 학습 수행 → 𝒄 의 정보가 지속적으로 갱신되고 있음을 의미
- 그리고 𝒄t 의 정보를 바탕으로 외부 계층과 다음 시각의 LSTM 계층에 𝒉t 를 계산하여 출력함
- Memory Cell은 어떤 값을 계산하는가?
- Ct는 3개의 입력(Ct-1, ht-1,x)로 부터 어떤 계산을 수행함
- 출력되는 은닉상태 𝒉t = 𝒕𝒂𝒏𝒉(𝒄t) (ht(은닉층)는 Ct의 영향을 받음)
- → 𝒄𝒕의 각 요소에 𝒕𝒂𝒏𝒉를 적용함을 의미
- 은닉상태 𝒉t 는 단순히 𝒄t 에 𝒕𝒂𝒏𝒉를 적용한 것 뿐이다
- → 𝒄t 와 𝒉t 를 구성하는 원소의 수는 같다
- Memory Cell은 무엇으로부터 제어를 받는가?
- 3개의 Gate와 1개의 Updater의 제어를 받음(gate: 데이터의 흐름을 제어)
- Output Gate
- Forget Gate
- Input Gate
- Updater → New Memory Cell
- 3개의 Gate와 1개의 Updater의 제어를 받음(gate: 데이터의 흐름을 제어)
- Output Gate
- tanh(ct)의 각 원소데 대해 "그것이 다음 시각의 은닉상태에 얼마나 중요한가?"를 조정
- 다음 은닉상태 ht의 출력을 담당하므로 output gate라고 부른다.
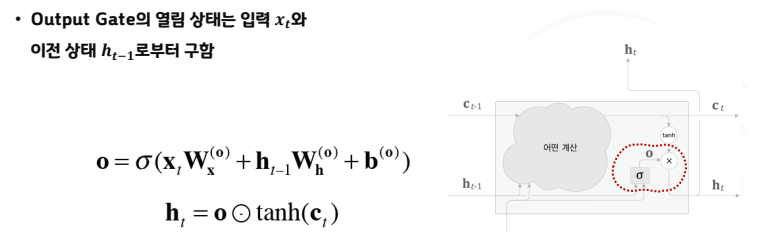
- Forget Gate
- 𝒄𝒕−𝟏의 기억 중에서 불필요한 “기억의 어떤 것을 잊을까?”를 명확하게 지시하는 Gate
- LSTM 계층에 Forget Gate를 추가하면..
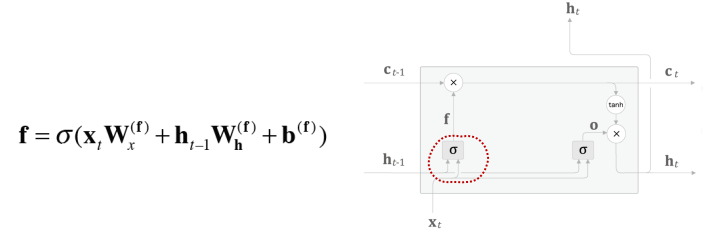
- Forget Gate
- 𝒄𝒕−𝟏의 기억 중에서 불필요한 “기억의 어떤 것을 잊을까?”를 명확하게 지시하는 Gate
- LSTM 계층에 Forget Gate를 추가하면..

- 새로운 Memory Cell
- 잊어야 할 기억은 삭제되었는데 새로운 기억은?
- 새로운 기억을 Memory Cell에 추가하기 위해서 tanh 노드 추가

- Input Gate
- g에 Gate를 하나 추가함 → 입력 게이트(input gate)
- g의 각 원소가 새로 추가되는 정보로서의 가치가 얼마나 큰지를 판단

- 어떻게 해서 Gate들과 새로운 Memory Cell이 기울기 소실을 해결하는가?
- Memory Cell "c"의 역전파를 보면 +, x 노드만을 지나게 됨
-3개의 Gate와 1개의 업데이트 메모리셀로 구성된 4개의 수식을 모아 단 한 번의 아핀변환으로 계산
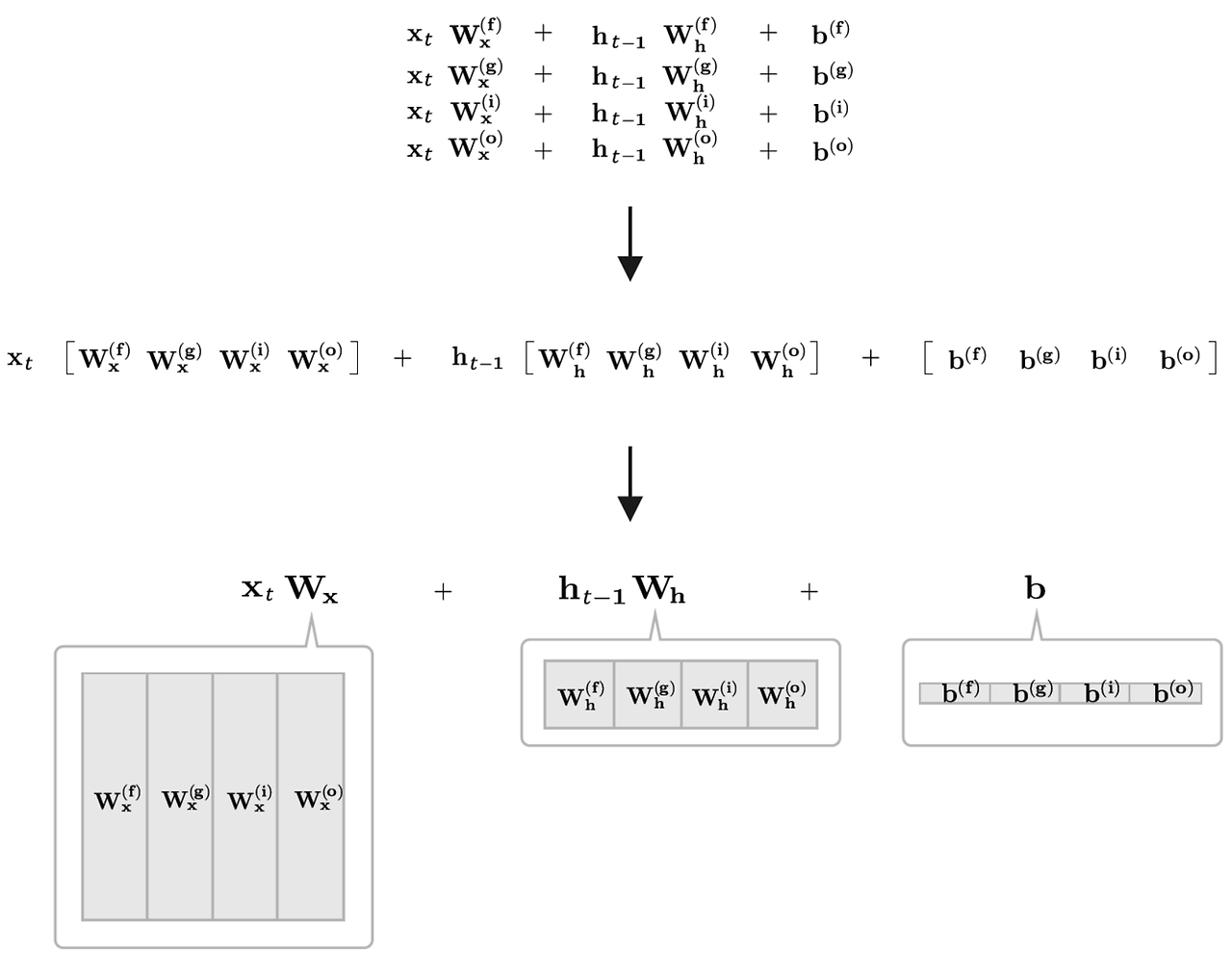
- 𝑾x , 𝑾h , 𝒃 각각에 4개 분의 가중치(혹은 편향)가 포함되어 있다고 가정하고 Affine 변환을 수행하는 LSTM 계산 그래프
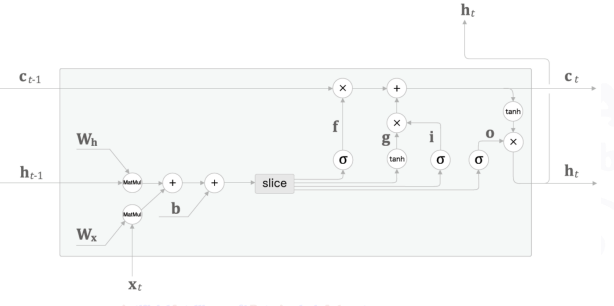
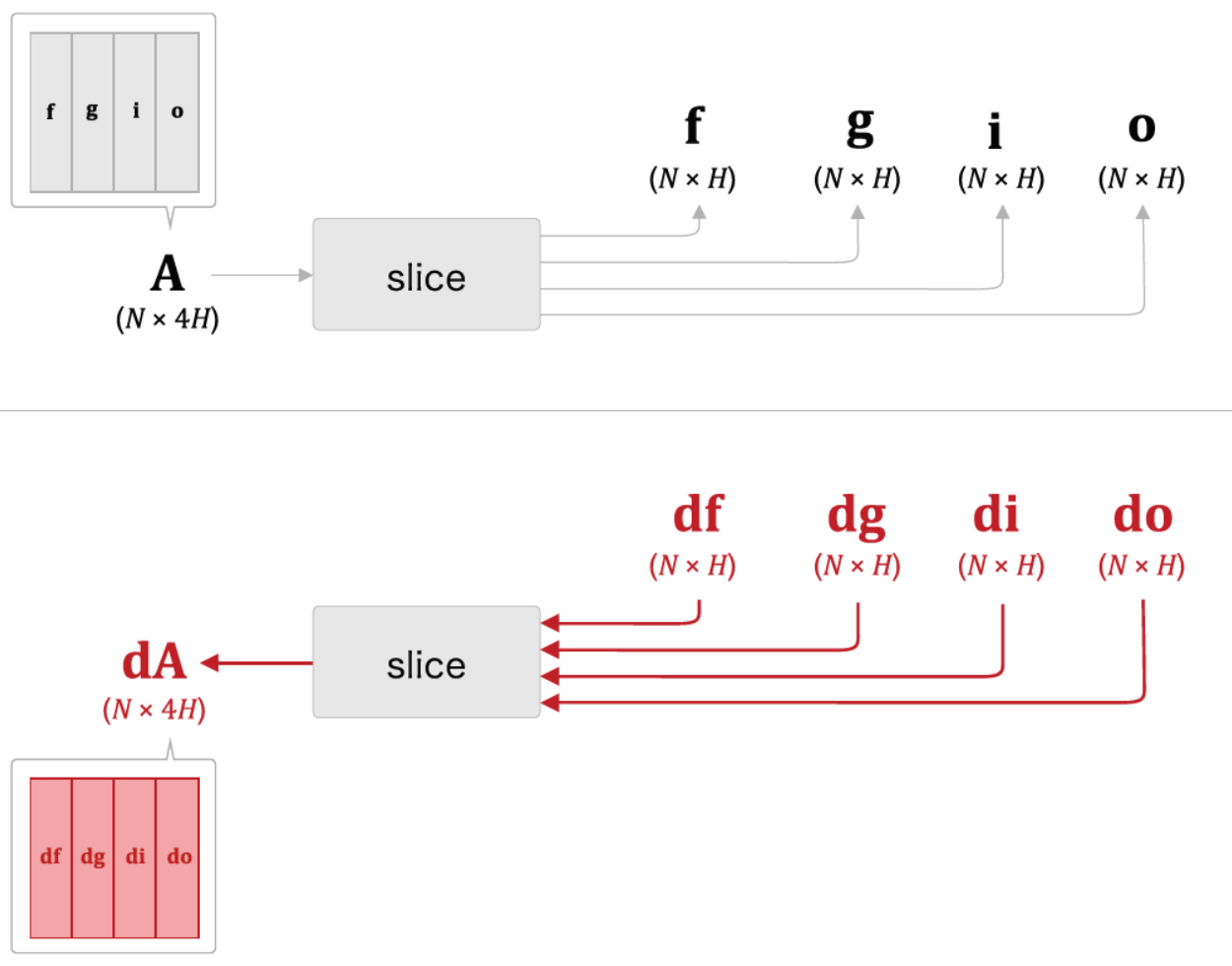
- Forget Gate를 통해 이전 특징 별로 기억 여부를 결정
- Input Gate를 통해 현 시점의 정보가 얼마나 중요한지를 반영하여 기록
- 이전 Cell State의 결과와 현 시점의 Forget Gate에서 잊고, Input Gate의 중요도만큼 곱한 값으로 현 시점의 Memory Cell값을 생성
- 현 시점의 Forget Gate, Input Gate에 의해서 변경된 현 시점의 Cell State 값을 얼마만큼 다음 레이 어로 전달할지 계산
728x90
'AI' 카테고리의 다른 글
| # 24.10.08_전처리:단어의 표현 + 임베딩 (5) | 2024.10.08 |
|---|---|
| # 24.10.07_자연어 처리 개요 + 전처리: 토큰화 (2) | 2024.10.07 |
| # 24.10.02_CNN모델의 이해 (1) | 2024.10.02 |
| # 24.10.01_PyTorch+TensorFlow학습 (0) | 2024.10.01 |
| # 24.09.30_AI(인공지능) 개요 + 딥러닝 개요 (3) | 2024.09.30 |


