다음 웹 페이지 개발 프로젝트를 진행하기에 앞서
데이터 분석과 ai가 들어간 웹 페이지를 개발하고 싶어서 데이터 자료를 찾던 중 네이버 웹툰 크롤링을 생각 해냈다.
네이버 웹툰 데이터를 직접 구글링을 통해 찾는것도 방법이긴 하겠지만, 가장 최근의 네이버 웹툰 부터 완결 웹툰들까지 다 지닌 데이터는 없을 거라고 판단하고 직접 크롤링하는 것을 생각해 내었다.
우선 크롤링을 하기에 앞서 크롤링할 때 많이 다운받아서 사용하는 크롬드라이버를 이용하기 위해 크롬 드라이버 다운로드 방법 부터 시작하겠다.
1. 먼저 구글 크롬 웹브라우저에 우측 상단 세로로 점 3개 를 클릭한 뒤 도움말 - chrome 정보에 들어간다.

2. chrome 버전이 나와있는데 이 버전을 확인해 주어야한다. (이 버전에 맞춰서 크롬 드라이버 설치)

3. https://developer.chrome.com/docs/chromedriver/downloads?hl=ko 사이트에 접속해준다.

위 동그라미친 부분에 들어간다.
4. 아래로 조그 스크롤하면 stable 표가 나오게 되는데 플랫폼에서 자신의 컴퓨터 운영체제에 맞는 URL을 선택해서 복붙해 주소창에 입력한다. (나의 경우 괄호친것 복사해서 주소창에 입력함)

5. 알집 파일로 다운로드 되어지고 이걸 풀면 아래와 같이 다운로드가 된다. (나의 경우 다운로드 폴더에 풀어줌)

네이버 웹툰 분석
아직까지는 구체적으로 분석에 대한 계획이 없었기 때문에 네이버 웹툰에서 연재 중인 작품들과 과거 완결 웹툰에 대한 기본적인 작품명, 작가, 평점, 주소 데이터를 수집하고자 했다.
(환경) python 3.12을 사용하고 requirements.txt 에 환경 저장
| attrs==24.2.0 beautifulsoup4==4.12.3 bs4==0.0.2 certifi==2024.8.30 cffi==1.17.1 charset-normalizer==3.4.0 h11==0.14.0 html5lib==1.1 idna==3.10 lxml==5.3.0 numpy==2.1.2 outcome==1.3.0.post0 pandas==2.2.3 pycparser==2.22 PySocks==1.7.1 python-dateutil==2.9.0.post0 pytz==2024.2 requests==2.32.3 selenium==4.25.0 six==1.16.0 sniffio==1.3.1 sortedcontainers==2.4.0 soupsieve==2.6 trio==0.27.0 trio-websocket==0.11.1 typing_extensions==4.12.2 tzdata==2024.2 urllib3==2.2.3 webencodings==0.5.1 websocket-client==1.8.0 wsproto==1.2.0 |
가상환경을 만들고 ( python -m venv webton) 현재 연재중인 작품들의 작품, 제목, 평점, 연재 요일을 가져오기로 정하였기에 네이버 웹툰 페이지에 접속해 페이지가 어떤 구성인지 파악해 보았다.

네이버 웹툰 홈에서는 크롤링이 힘들 것 같아서, 웹툰 탭에 요일별 웹툰 탭으로 들어가 보았다.
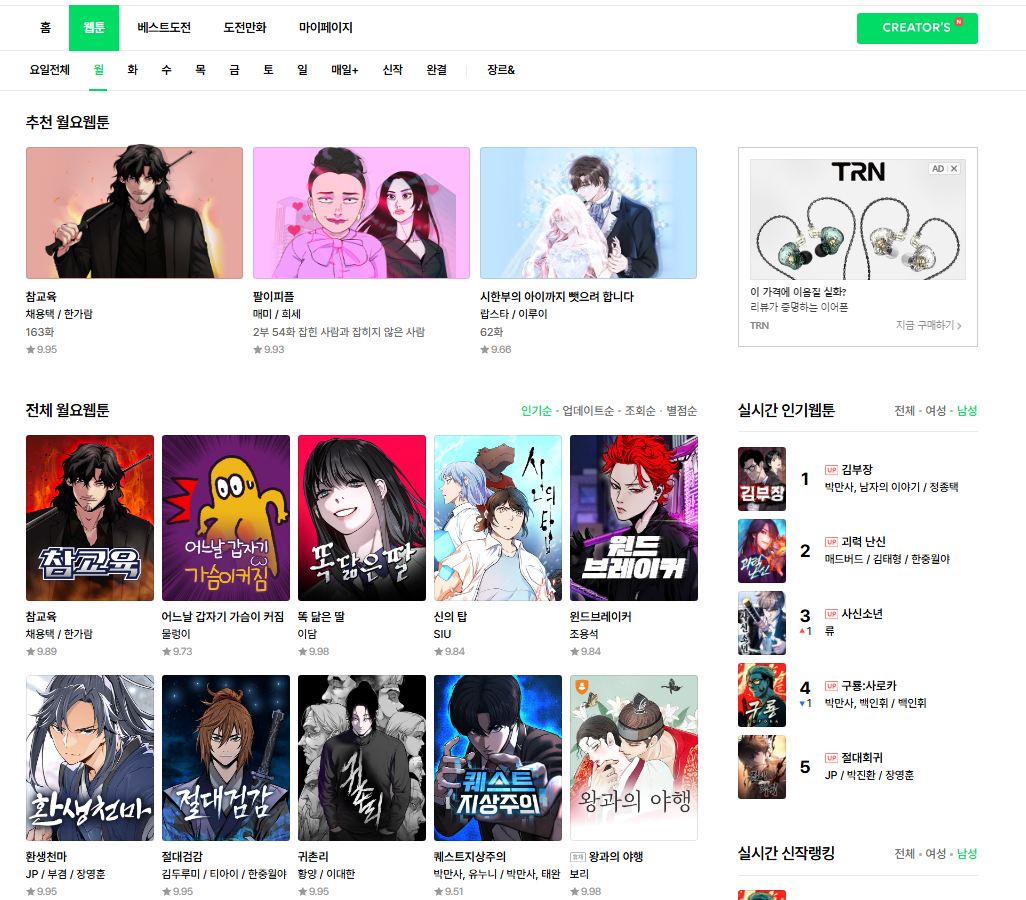
요일별 웹툰 탭에 들어가 보니 제목, 저자명, 평점이 한번에 나와있는 것을 볼 수 있었다.
이에 Selenium 을 사용하여 동적으로 로딩되는 웹 페이지에서 데이터를 수집하는 방식을 적용해 크롤링을 적용해 보았다.
처음에는 request 모듈로 각 요일 페이지의 소스코드를 가져오는 것으로 생각했었는데, 웹 페이지의 콘텐츠가 JavaScript로 로딩 될 수 있기 때문에 Selenium을 사용하는 것으로 바꿔 적용했다. (Selenium은 브라우저를 직접 조작하여 이러한 동적 콘텐츠를 로드할 수 있기 때문에)
코드 설명
1. 필요 모듈 가져오기
| from selenium import webdriver from seleniuhttp://m.webdriver.chrome.service import Service from seleniuhttp://m.webdriver.common.by import By from bs4 import BeautifulSoup import pandas as pd import time |
- selenium: 웹 브라우저 자동화를 위해 사용
- BeautifulSoup: HTML 및 XML 문서를 파싱하여 데이터를 추출하기 위해 사용
- pandas: 데이터프레임을 생성하고 CSV 파일로 저장하기 위해 사용
- time: 프로그램 실행을 일시 중지하기 위해 사용
2. ChromeDriver 경로 설정 및 브라우저 열기
| chrome_driver_path = "C:/Users/kgw08/Downloads/chromedriver-win64/chromedriver.exe" service = Service(chrome_driver_path) driver = webdriver.Chrome(service=service) |
- ChromeDriver의 경로를 지정하고, 이를 이용해 Chrome 브라우저를 열어 줍니다.
- 나의 경우 downloads폴더에 그냥 풀었음으로 해당 경로로 설정
3. URL 및 데이터프레임 초기화
| h = 'https://comic.naver.com/webtoon/weekdayList?week=' day = ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun', 'dailyplus', 'new', 'finish'] df = pd.DataFrame(columns=['days', 'title', 'author', 'rating', 'url']) |

네이버 웹툰의 요일별 기능을 보면 https://comic.naver.com/webtoon/weekdayList?week= 까지는 동일하며 뒷부분에 요일이 및 dailyPlus, new, finish 가 붙는 식으로 홈페이지가 동작하는 것을 확인했고 이를 토대로 코드를 설정해서 진행함
- 각 요일에 대한 URL을 생성하기 위한 기본 URL과 요일 목록을 설정
- 요일, 제목, 작가, 평점, 페이지 주소 총 5개의 정보를 가져오고자 이를 데이터 프레임으로 만든다.
- 수집할 정보를 저장할 데이터프레임을 초기화합니다.
4. 각 요일에 대한 웹툰 데이터 수집
| for i in day: driver.get(h + i) time.sleep(2) # 페이지 로딩 대기 |
- 각 요일의 URL을 생성하고 해당 페이지를 열어주는데. time.sleep(2)는 페이지가 완전히 로딩될 때까지 대기 해줍니다.
- 반복문을 써주면 페이지의 주소를 for문을 통해 각각 가져올 수 있다.
5. 페이지 스크롤 및 데이터 수집
| last_height = driver.execute_script("return document.body.scrollHeight") # 현재 문서 높이 while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(2) # 페이지 로딩 대기 new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: break last_height = new_height |
- 페이지의 끝까지 스크롤하여 모든 콘텐츠가 로딩되도록 해줍니다. 새로 로딩된 페이지의 높이를 확인하고, 이전 높이와 같으면 더 이상 스크롤할 필요가 없으므로 루프를 종료하게 됩니다.
- 끝까지 스크롤 하는 이유는 네이버 웹툰 완결쪽에서 보면 웹툰의 수가 많아서 스크롤을 내리면 계속해서 웹툰이 나오는 것을 확인하였기에 스크롤을 적용했습니다.
6. BeautifulSoup으로 페이지 소스 파싱
| soup = BeautifulSoup(driver.page_source, 'html.parser') |
- Selenium이 가져온 페이지 소스를 BeautifulSoup으로 파싱하여 HTML 구조를 분석합니다.
7. 웹툰 데이터 추출
| data = soup.find('ul', {'class': 'ContentList__content_list--q5KXY'}) if data is None: print(f"'{i}' 페이지에서 'ContentList__content_list--q5KXY' 클래스를 찾을 수 없습니다.") continue items = data.findAll('li', {'class': 'item'}) |
- 웹툰 목록을 포함하는 ul 요소를 찾고, 해당 요소가 없을 경우 에러 메시지를 출력합니다.
- li 요소들을 찾고, 각 웹툰에 대한 정보를 추출합니다.
8. 개별 웹툰 정보 수집 및 데이터 프레임에 추가
해당 작업에 앞서 웹페이지에 대한 html요소를 알아볼 필요가 있는데, 웹페이지에서 마우스 오른쪽 클릭 후 '검사' 를 누르거나 F12를 누르면 개발자 도구가 나온다. Elements 를 클릭한 후 확인하고 싶은 곳에 올려두면 아래 이미지와 같이 파란색으로 화면이 변하며 다시 클릭하면 해당 부분의 html요소를 확인 가능하다.

이후에 div > ui > li > dl 로 깊이 내려간 후 dt, dd 등에서 웹툰에 대한 기복적인 정보를 확인한다. 이를 토대로 개별 웹툰 정보 수집을 진행하는 코드를 작성하면 되는 것이다.

| for item in items: title_element = item.find('span', {'class': 'text'}) title = title_element.text.strip() if title_element else '제목 없음' author_element = item.find('a', class_='ContentAuthor__author--CTAAP') author = author_element.text.strip() if author_element else '저자 정보 없음' rating_element = item.find('span', class_='Rating__star_area--dFzsb') rating = rating_element.text.strip().replace('별점', '').strip() if rating_element else 'N/A' url = 'https://comic.naver.com' + item.find('a')['href'] df = pd.concat([df, pd.DataFrame([[i, title, author, rating, url]], columns=['days', 'title', 'author', 'rating', 'url'])], ignore_index=True) |
- 각 li 요소에서 웹툰 제목, 저자, 평점, URL을 추출합니다. 추출한 데이터를 데이터프레임에 추가한다.
9. 브라우저 닫기 및 csv로 저장
| driver.quit() df.to_csv('webtoon_data_scrolled.csv', index=False, encoding='utf-8-sig') print(df) |
- 크롤링이 끝난 후 브라우저를 닫고, 수집한 데이터를 CSV 파일로 저장해준다.
이것으로 Selenium을 사용해 동적으로 로딩되는 웹 페이지에서 데이터를 수집하는 방식을 살펴봤고, 이를 통해 네이버 웹툰의 현재와 과거 웹툰들의 기본 정보를 csv파일로 얻을 수 있게 되었다.
아직 프로젝트 주제가 확실하게 정해지지는 않은 상황이라 이데이터를 이용할지 아님 다른것을 이용할지에 대해서는 팀원들과 의견을 조율해 보아야 겠다.